AzureのOCRサービス「Azure Form Recognizer」入門
注意
サービス名称に伴い最新版の記事はこちらに記載しました。
https://ohina.work/post/azure_ocr_di/#google_vignette
はじめに
Azureには、Azure Cognitive ServicesとAI機能をWeb APIして提供するサービスがあります。
本記事では、Azure Cognitive Servicesのうち、OCRサービス「Azure Form Recognizer」の使い方について紹介します。
Azure Cognitive Servicesとは
Azure Cognitive Servicesは、視覚、音声、言語、決定、検索の5ジャンルからなるAI機能をWeb APIとして利用できるAzureのサービスです。
https://azure.microsoft.com/ja-jp/services/cognitive-services/#overview
Azure Form Recognizerとは
請求書、レシート、名刺などのドキュメントから文字情報を取得するAzure Cognitive ServicesのOCR機能の一つです。
Azure Form RecognizerのAPIを実行すると、リクエスト時で渡されたPDFファイルなどのドキュメントのURLを解析し、 解析したテキスト情報をHTTPレスポンスとして返します。

https://docs.microsoft.com/ja-jp/azure/applied-ai-services/form-recognizer/
もう一つのOCRサービス「Azure Computer Vision」
Azure Cognitive ServicesのOCRサービスには、Computer Visionというものもあります。
Computer Visonは画像やビデオのコンテンツを分析するAIサービスです。
こちらもOCRの機能がありますが、画像内のオブジェクトの検出、画像の説明の生成、顔認識などOCR以外にも、画像に対してより幅広いことができます。
PDFファイルの上の表にあるテキストの取得や、指定したテキストを取得したい場合は、Azure Form Recognizerの方が適しています。
https://stackoverflow.com/questions/71071309/ai-form-recognizer-vs-cognitiveservices-computervision
https://azure.microsoft.com/ja-jp/services/cognitive-services/computer-vision/#overview
https://www.alirookie.com/post/azure-ocr-with-pdf-files
Azure Form Recognizerの機能
Azure Form Recognizerは、機能で、次のサービスで構成されています。
- Layout API
- 事前構築済みモデル
- カスタムモデル
Layout API
Azure Form RecognizerのAPIを実行することで、ドキュメントから、テキストや、テーブルの構造、テキスト、バウンディングボックスの座標と共にドキュメントから抽出します。
事前構築済みモデル(Prebuilt Model)
事前構築済みモデルは請求書、レシート、名刺などMicrosoftが事前に用意している特定のドキュメント専用のAIモデルを使用して、フォームを解析する機能です。
カスタムモデル
カスタムモデルは、ユーザが独自に作成することができるAIモデルです。
事前構築済みモデルに用意されていないオリジナルのフォームを解析する場合は、カスタムモデルが必要です。
https://docs.microsoft.com/ja-jp/azure/applied-ai-services/form-recognizer/concept-custom
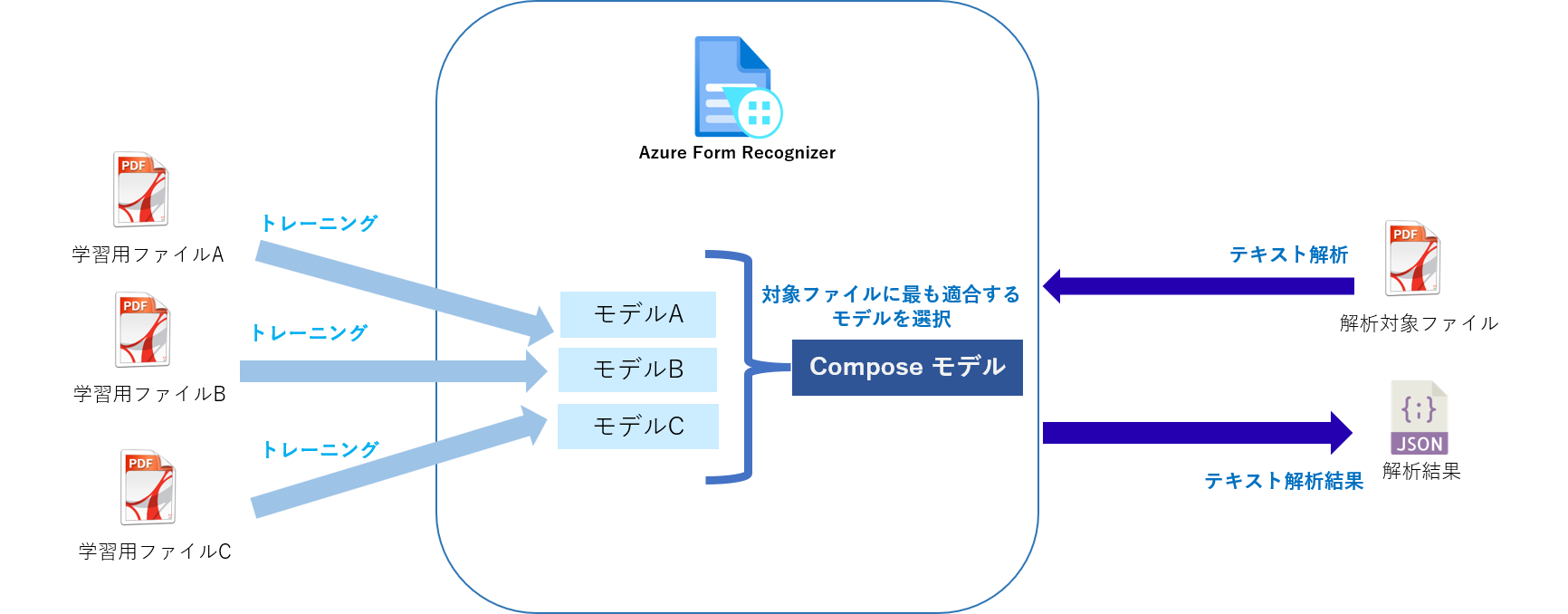
Composeモデル(複合モデル)
Composeモデルは複数のカスタムモデルを組み合わせたモデルです。
Composeモデルに対してテキスト解析要求を実行すると、設定したカスタムモデルの中から要求を受けたファイルが最も適合する割り当てモデルを選択し、そのモデルの結果を返します。
最大100個の学習済みカスタムモデルを1つのComposeモデルに割り当てることができます。
https://westus.dev.cognitive.microsoft.com/docs/services/form-recognizer-api-v2-1/operations/Compose
Azure Form Recognizerを作成する
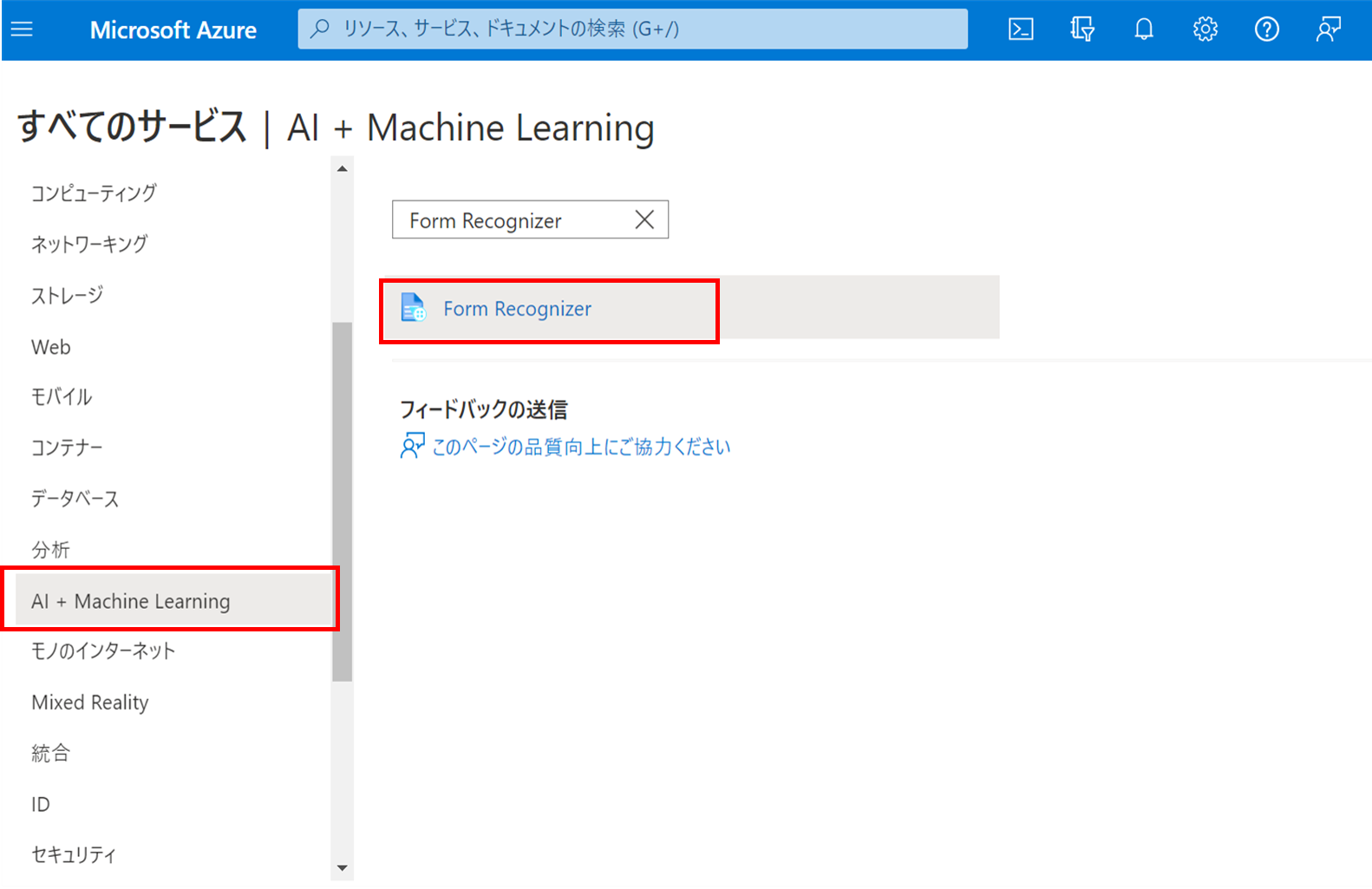
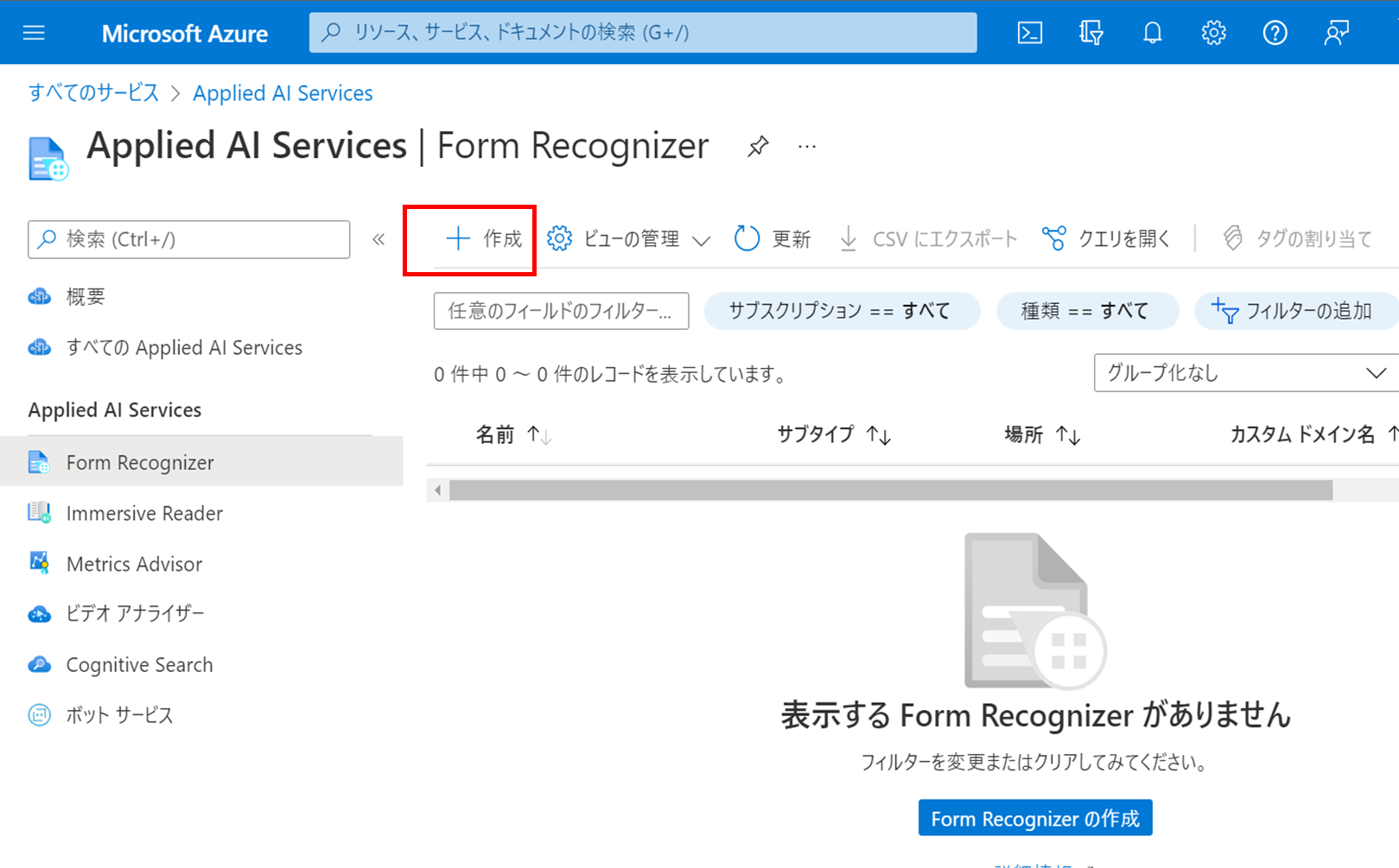
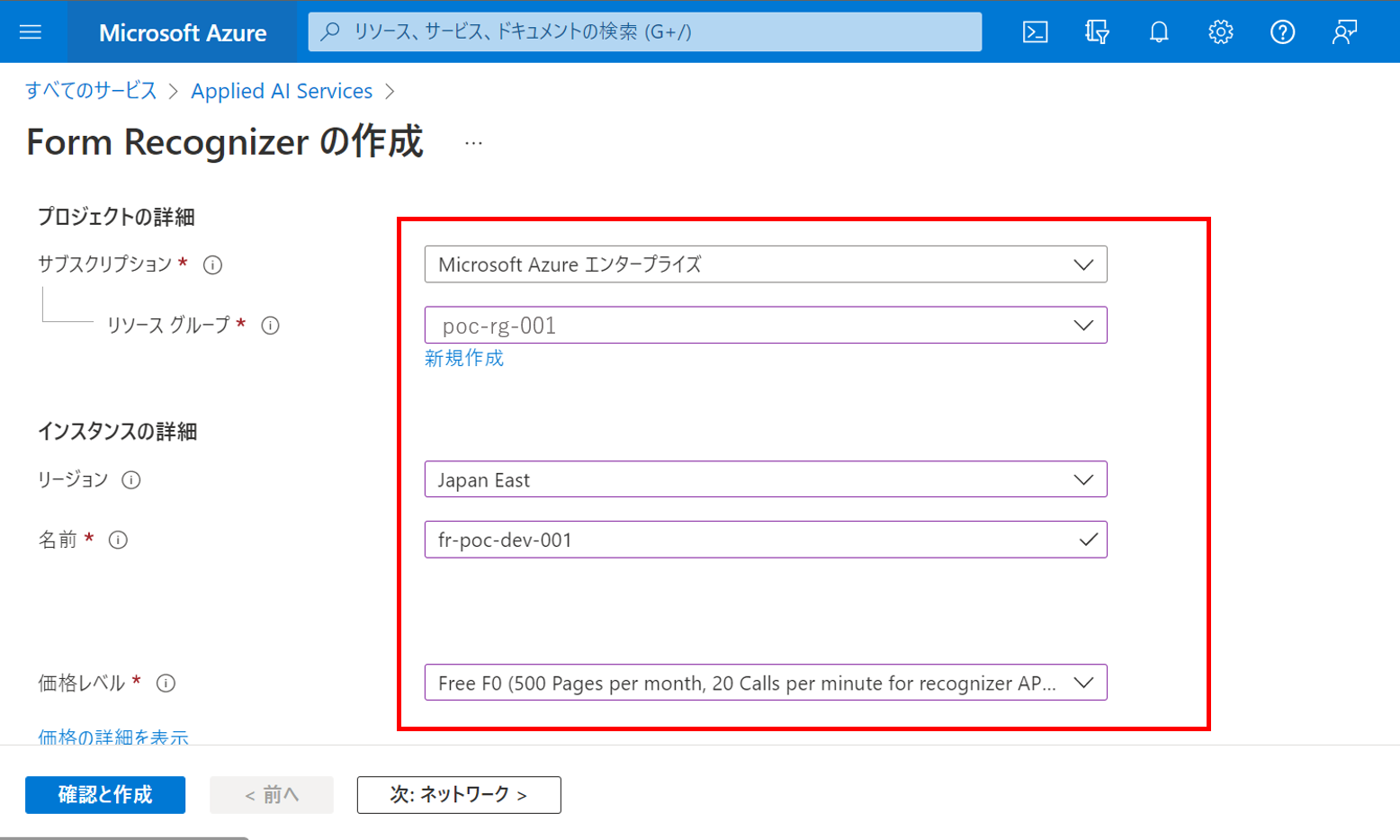
Azure Form Recognizerのリソースを作成するには、Azureポータルから以下のように画面遷移します。
今回はAzure Form Recognizerは、無料プランで作成し、インターネットからのアクセスを前提とします。
ラベリングtoolを使ってモデルを作成
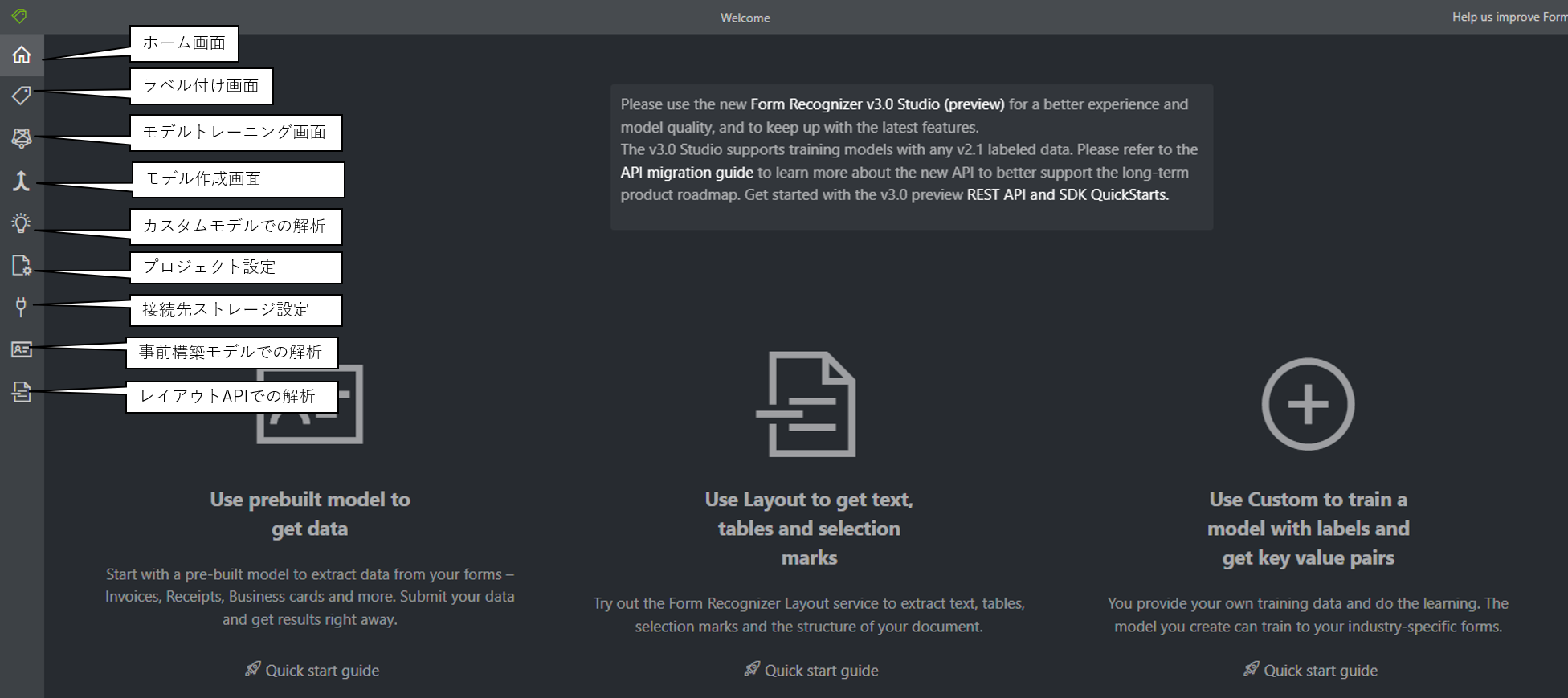
Azure Form Recognizerでモデルを作成する場合、以下の方法があります。
- WEBブラウザを使ったラベリングtoolを使ってGUIでモデルを作成する
- Azure SDKや、Rest APIでコードベースでモデルを作成する
後者の場合、解析が必要なドキュメントに合わせて、つどコードの作成が必要なので、 サンプルのラベリングtoolを使うことを推奨します。
ラベリングtoolは以下のURLから利用することができます。
https://fott-2-1.azurewebsites.net/layout-analyze
https://qiita.com/komiyasa/items/afee82f7baddcd820251
接続先のBlobストレージの設定
ラベリングtoolを利用するにために、最初にForm RecoginzerがOCRを実施するPDFファイルが配置されたBlobストレージのコンテナを指定する必要があります。
Blobストレージ接続設定は以下のように実施します。
アクセスするBLOBストレージアカウントのCORSを有効にする
Azureポータルから以下の設定を実施します。
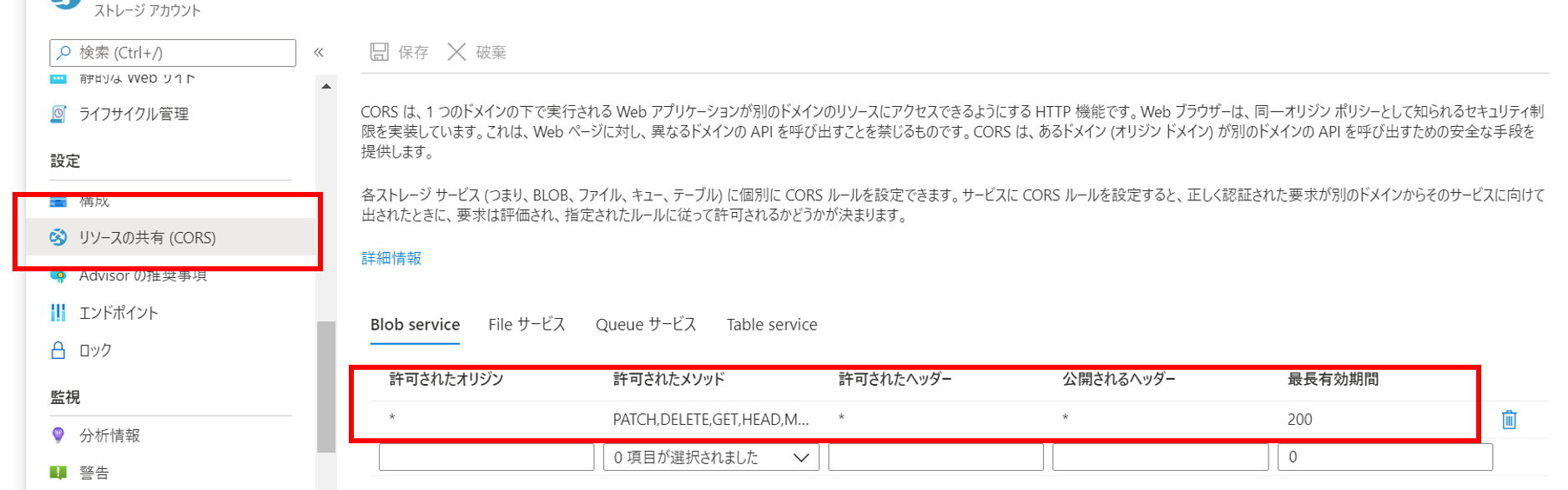
CORS設定しない場合は、ラベリングtoolで "if you have unexpected read/write/list/delete"というエラーメッセージが表示されます。
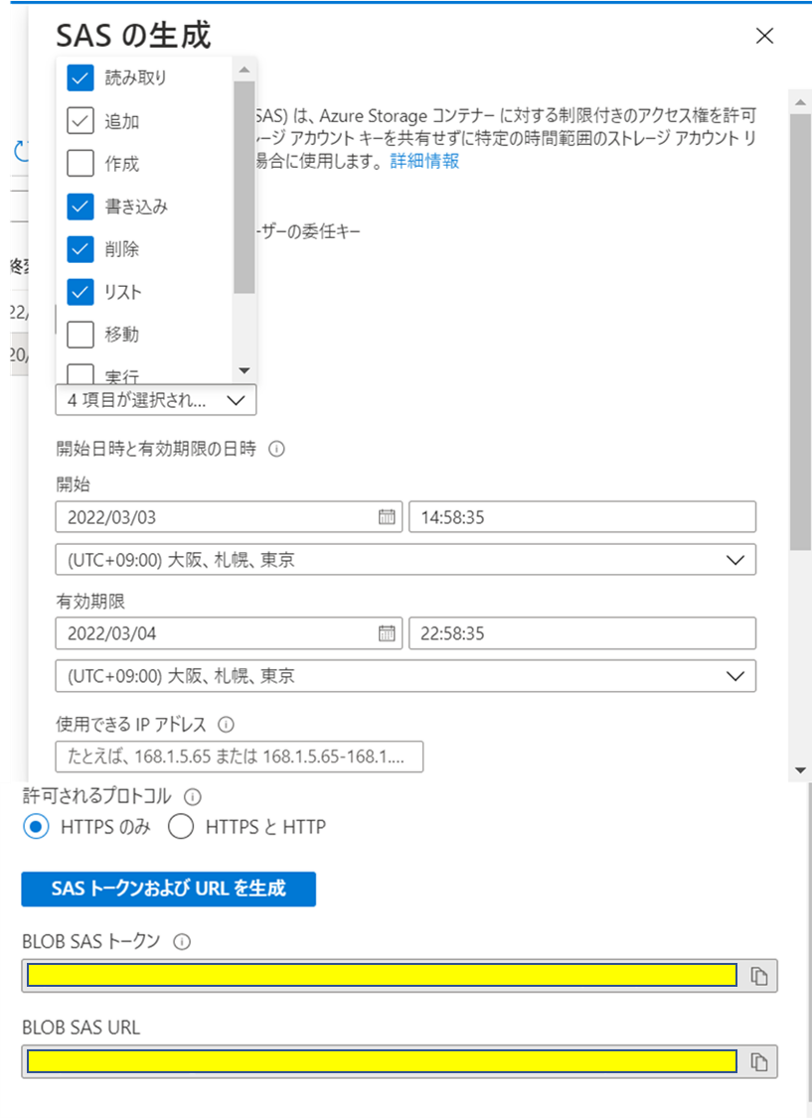
コンテナのSASの発行
Azureポータルで接続させる対象のBlobコンテナから読み取り、書き込み、リスト、削除の権限を持つSASを発行します。
ストレージアカウントではなく、コンテナのSASを発行する必要があります
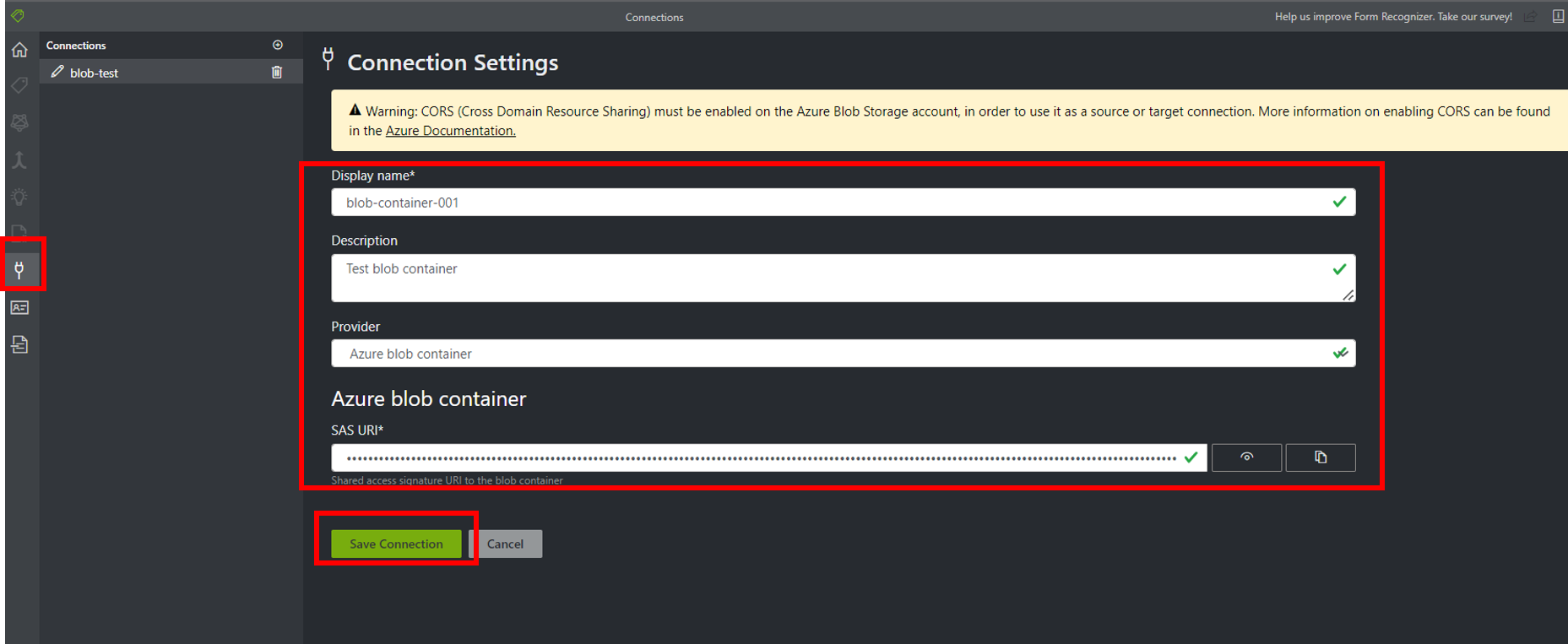
ラベリングtoolに設定
ラベリングtoolに接続先のBLobのコンテナ名と発行したSASを設定します。
プロジェクト作成
次に、プロジェクトを作成し、先程作成したBlobストレージの接続情報と、機会学習に使用する画像ファイル、FormRecognizerのURLとAPIキーをラベリングtoolに設定します。
URLとAPIキーはAzureポータルから取得することができます。
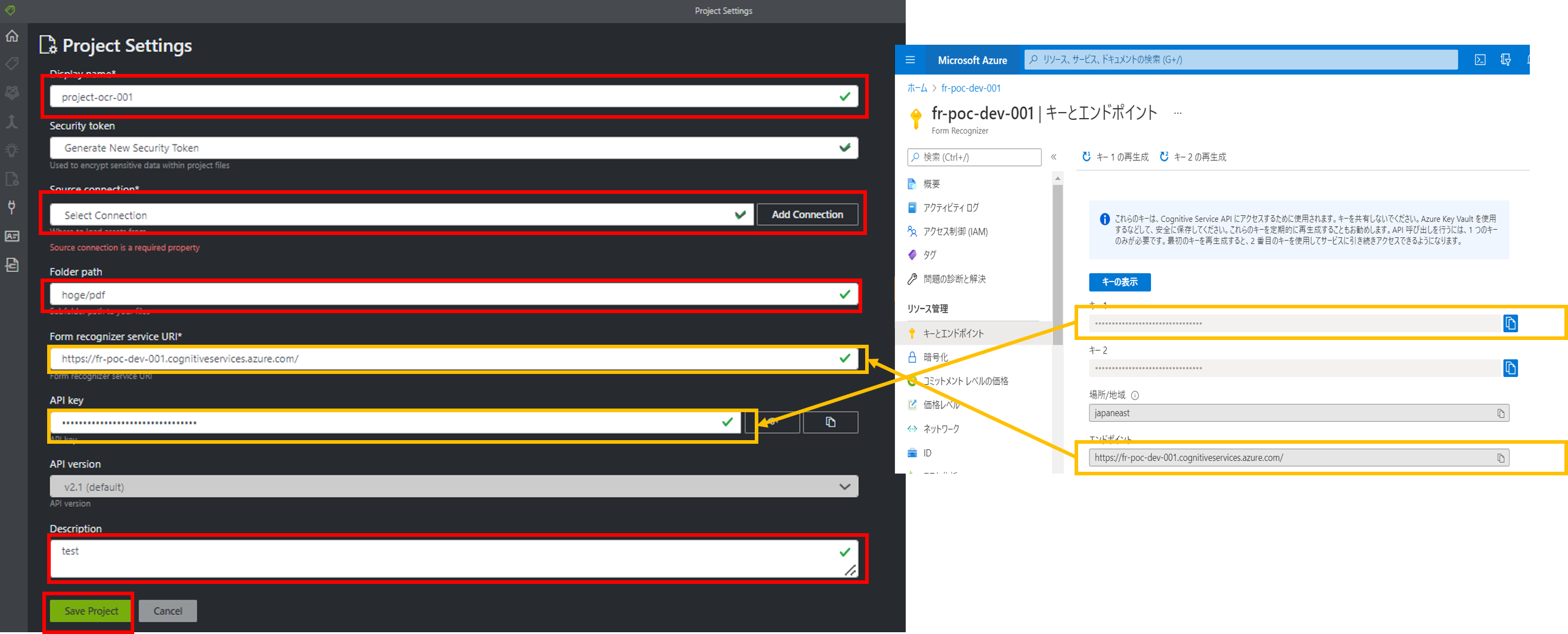
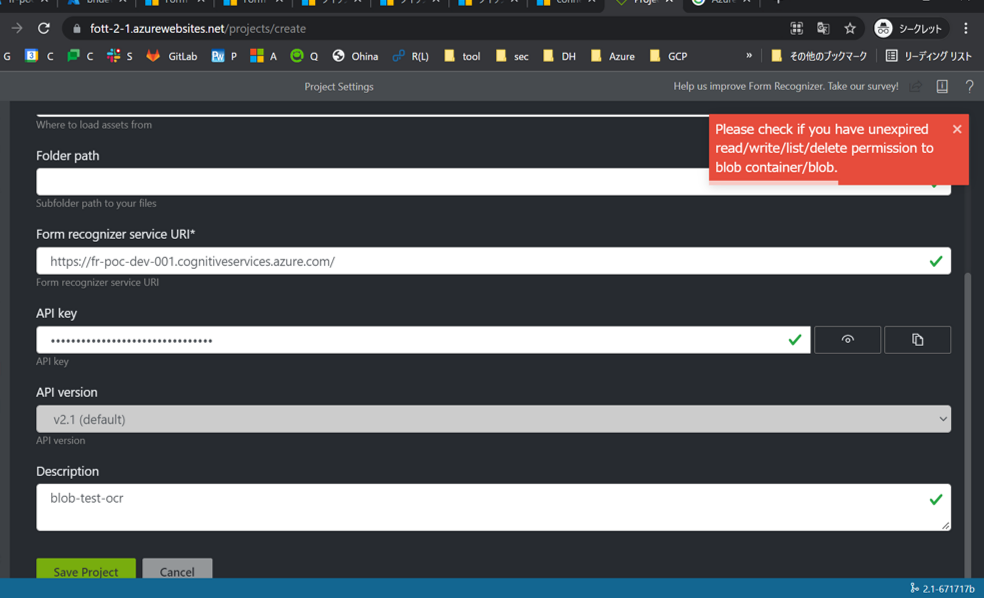
CORSの設定をしても、"if you have unexpected read/write/list/delete" というエラーが出る場合、プロジェクト設定で、接続先のコンテナの設定をフォームを選択する場合は解除が必要
プロジェクトを作成するとプロジェクト名.fottというファイルが接続先のストレージアカウントのコンテナ直下に作成されます。
プロジェクト作成後はラベルタブで抽出対象のテキストにラベルをつけたり、分析タブを使ってOCRでテキストを抽出したりすることができるようになります。
ラベリングtoolの使い方
ラベリングtoolのラベルタブを指定すると、プロジェクトに設定したディレクトリ配下のファイルに対して、OCRが実行されます。
下図にあるように黄色にラインが引かれている箇所がOCRでテキストとして認識された箇所になります。
また、PDFファイル上に表示されるテーブルアイコンをクリックすると、テーブルとして認識されているテキストの情報が表示されます。
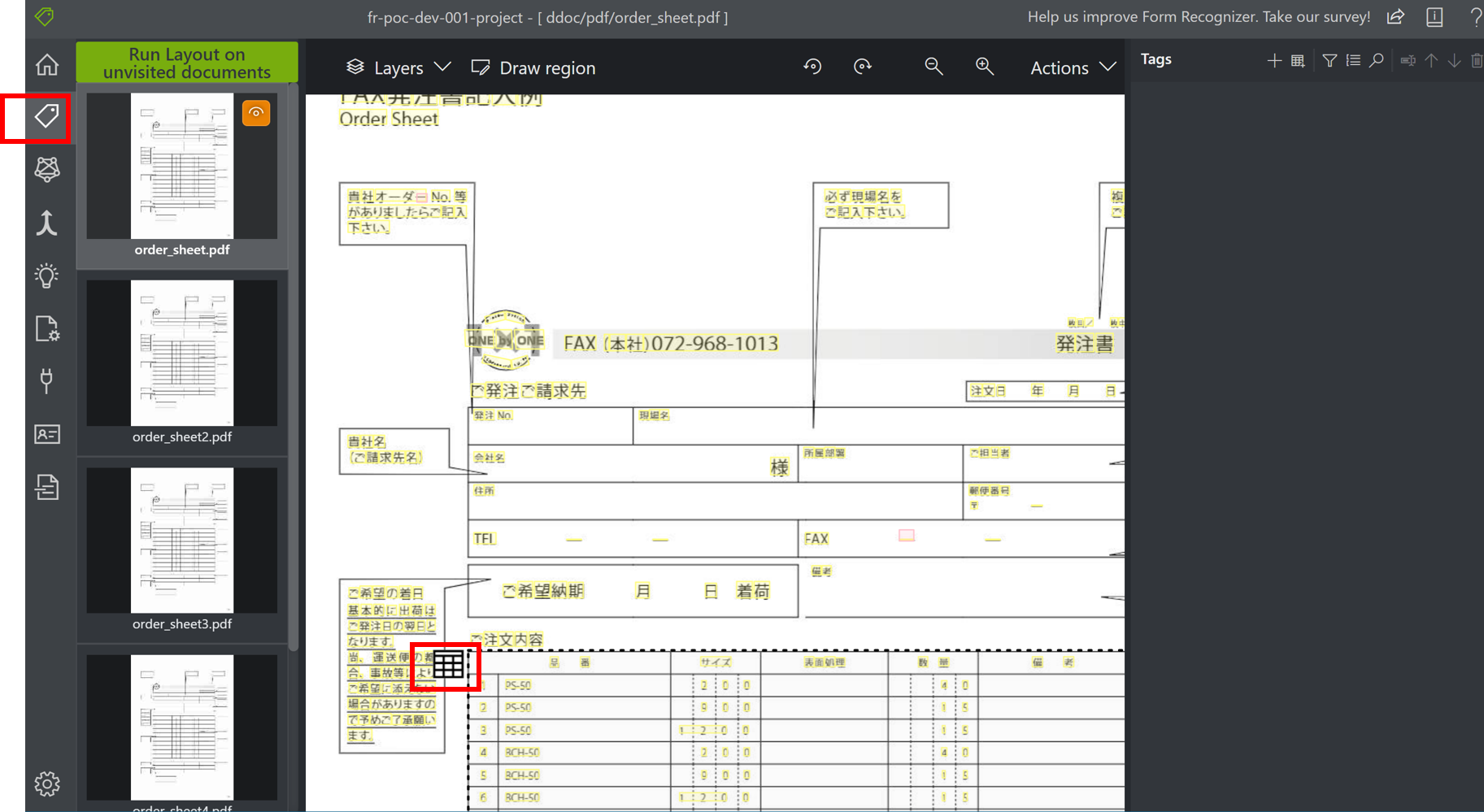
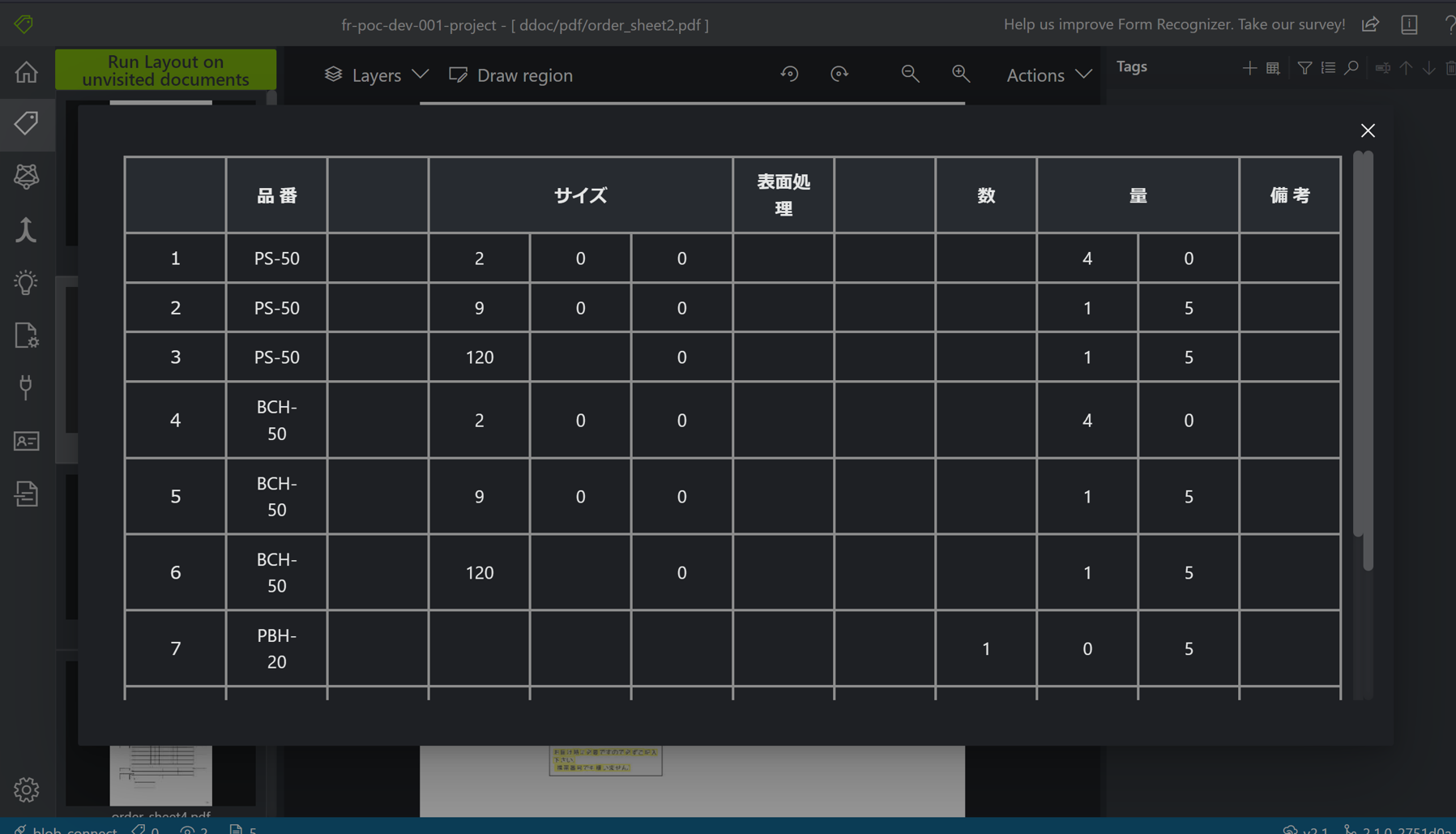
テーブルとして認識されているテキストは、テキスト解析後するとテーブルの構造を取得することができ、どのテキストがどの行番号、どの列番号にあるかを取得することができます。
タグ付け
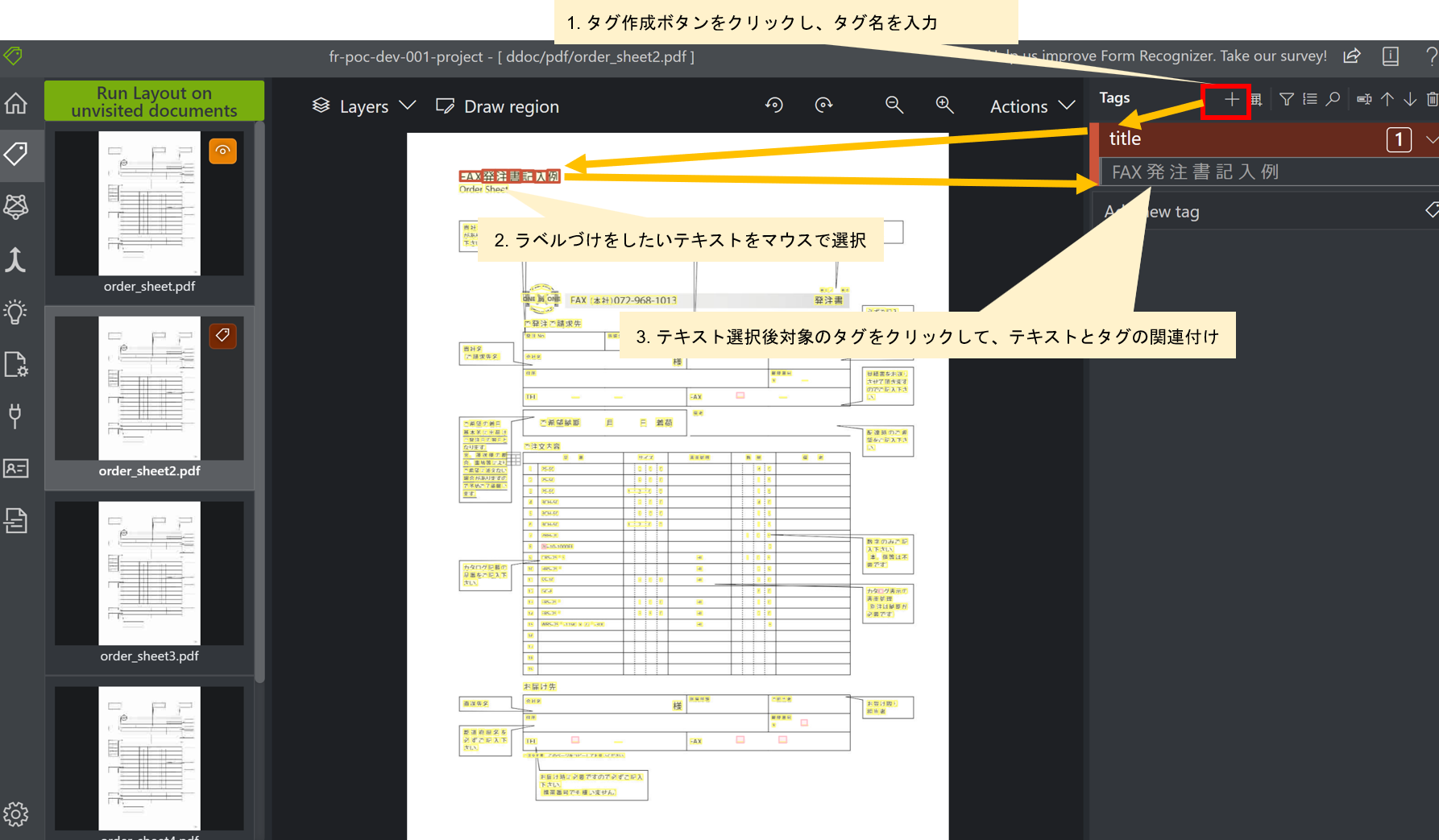
ラベリングtoolではOCRで解析したテキストに対して、タグ(ラベル)付けをつけることができます。
例えば、FAX発注書記入例というファイルのタイトルにtitleというそのテキストの内容を意味するタグ名を設定することができます。
タグは以下の操作を実行することで、設定することができます。
- タグ作成ボタンをクリックし、タグ名を入力
- ラベルづけをしたいテキストをマウスで選択
- テキスト選択後、対象のタグをクリックして、テキストとタグを関連付けする
タグ付けを行うメリットは以下の通りです。
- タグ付けによりモデルの精度が向上する
- タグ名から検索を行うことで、OCR解析結果からタグ付けしたテキストのみを抽出することができるようになる
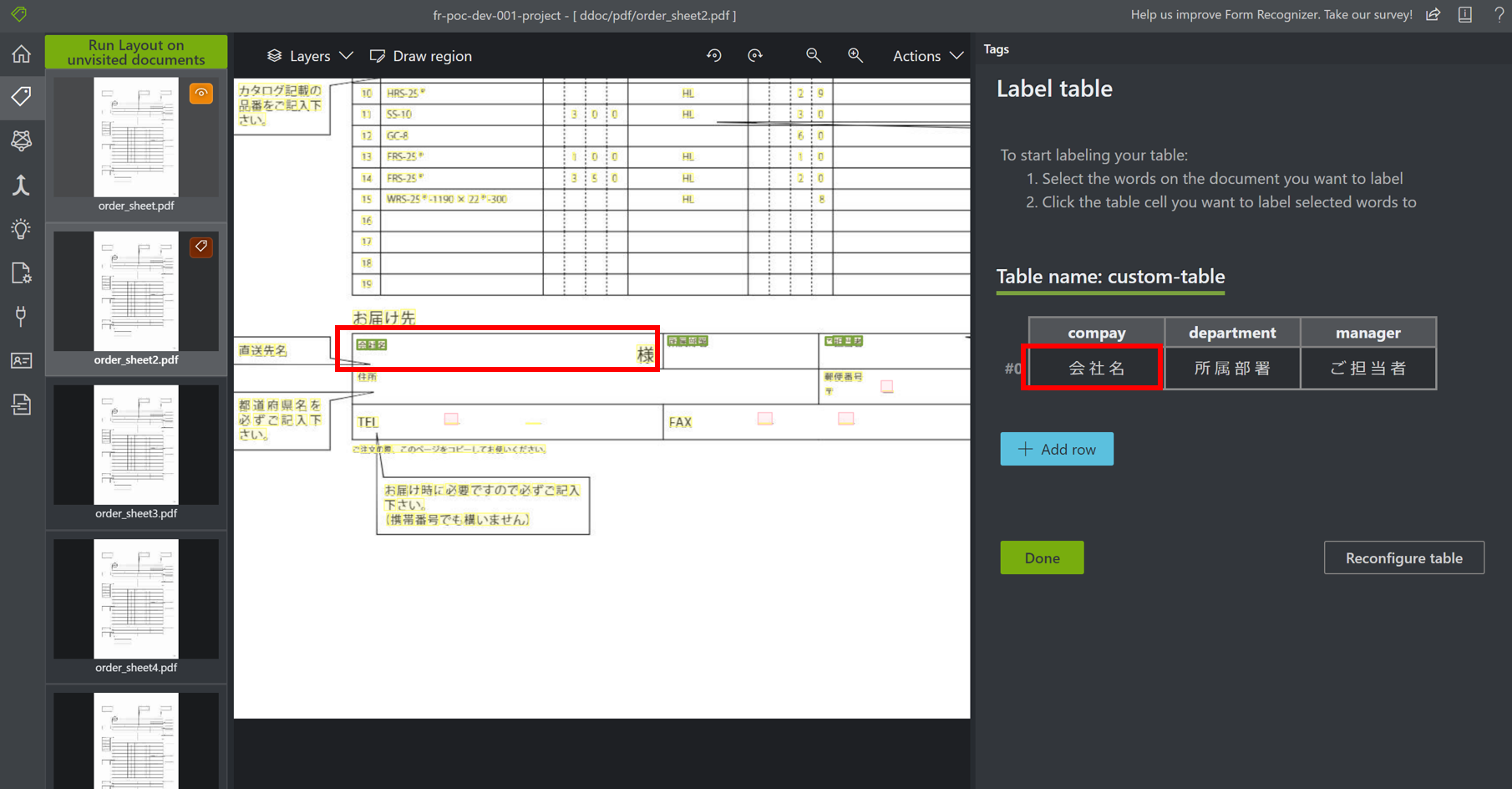
テーブルタグ
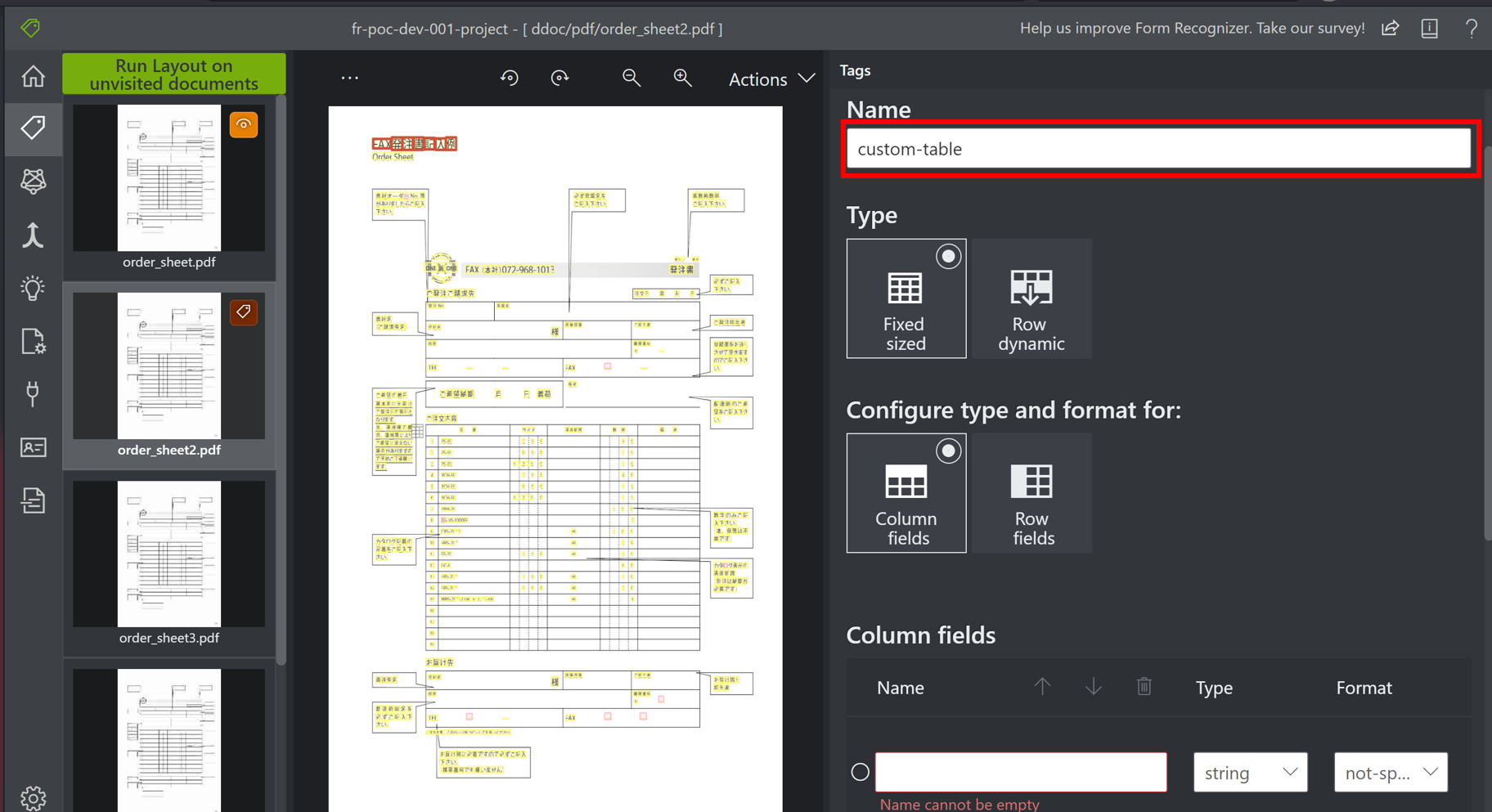
テーブル形式のタグも設定することも可能です。
デフォルトでもテーブル認識機能はついていますが、結合セルがあったり表の形式が不規則だと、テーブルとして認識されないことがあります。
このようなケースでは、テーブルタグを作成し、ファイル中のテーブルと関連付けを行う必要があります。
テーブルタグは以下の手順で設定します。
- テーブルタグ作成ボタンをクリックし、タグ名を入力
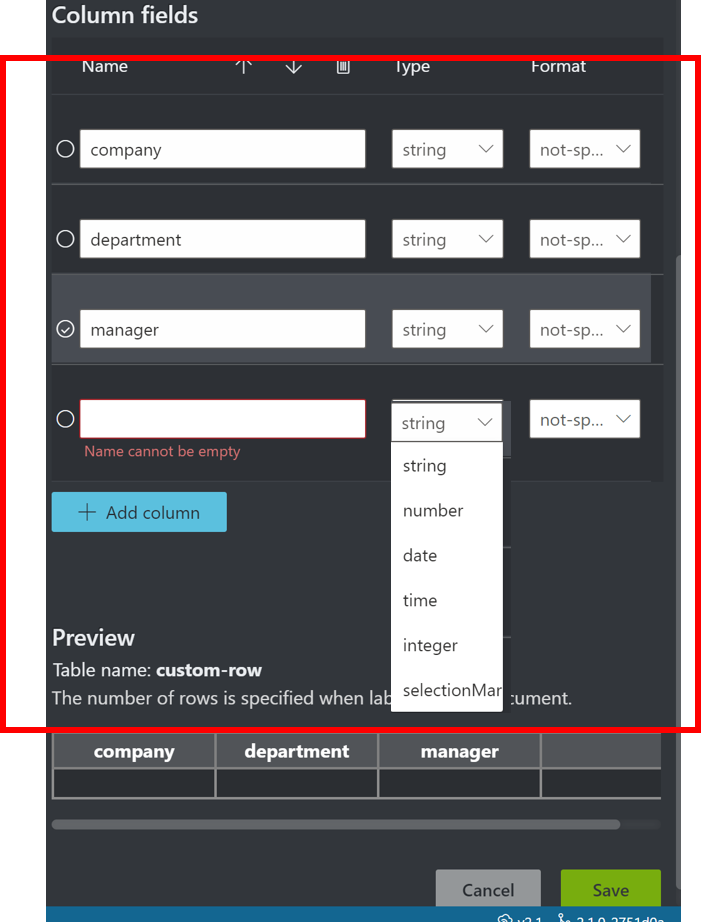
- テーブルタグの列名と列の型を指定し、テーブルタグを作成
- 作成したテーブルタグをクリック
- テキスト選択後、対象のテーブルタグの列をクリックし、テキストとテーブルタグを関連付けする
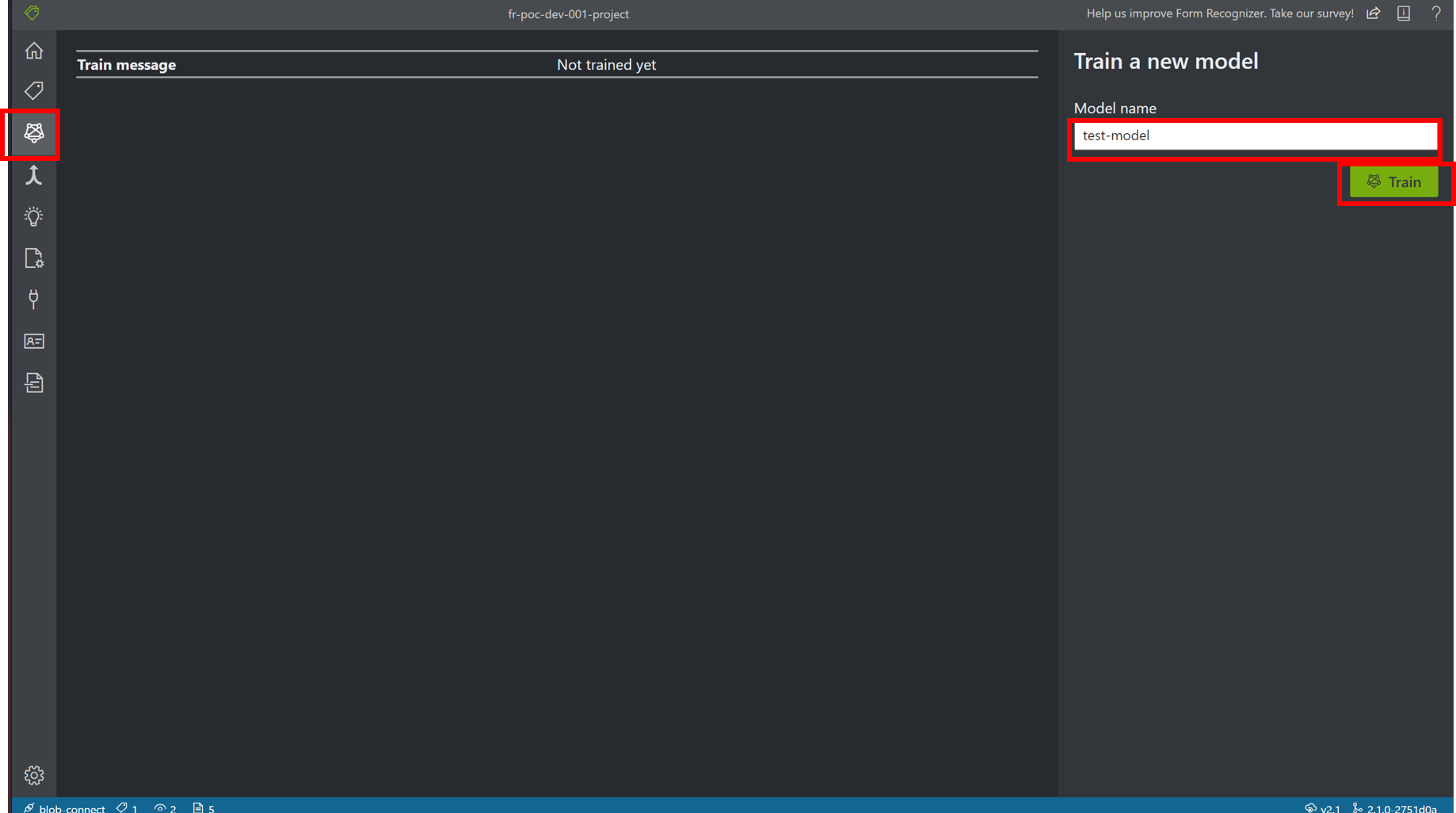
モデル作成
トレーニングタブを選択後、Trainボタンをクリックすると、ラベルタブの操作で読み込んだPDFファイルと設定したラベル情報にもとづいて、 機会学習が行われ、モデルが作成されます。
テキスト解析
アナライズタブをクリックして、テキスト抽出したいファイルをアップロードすると、作成したモデルにもとづいて、 テキスト解析が行われます。
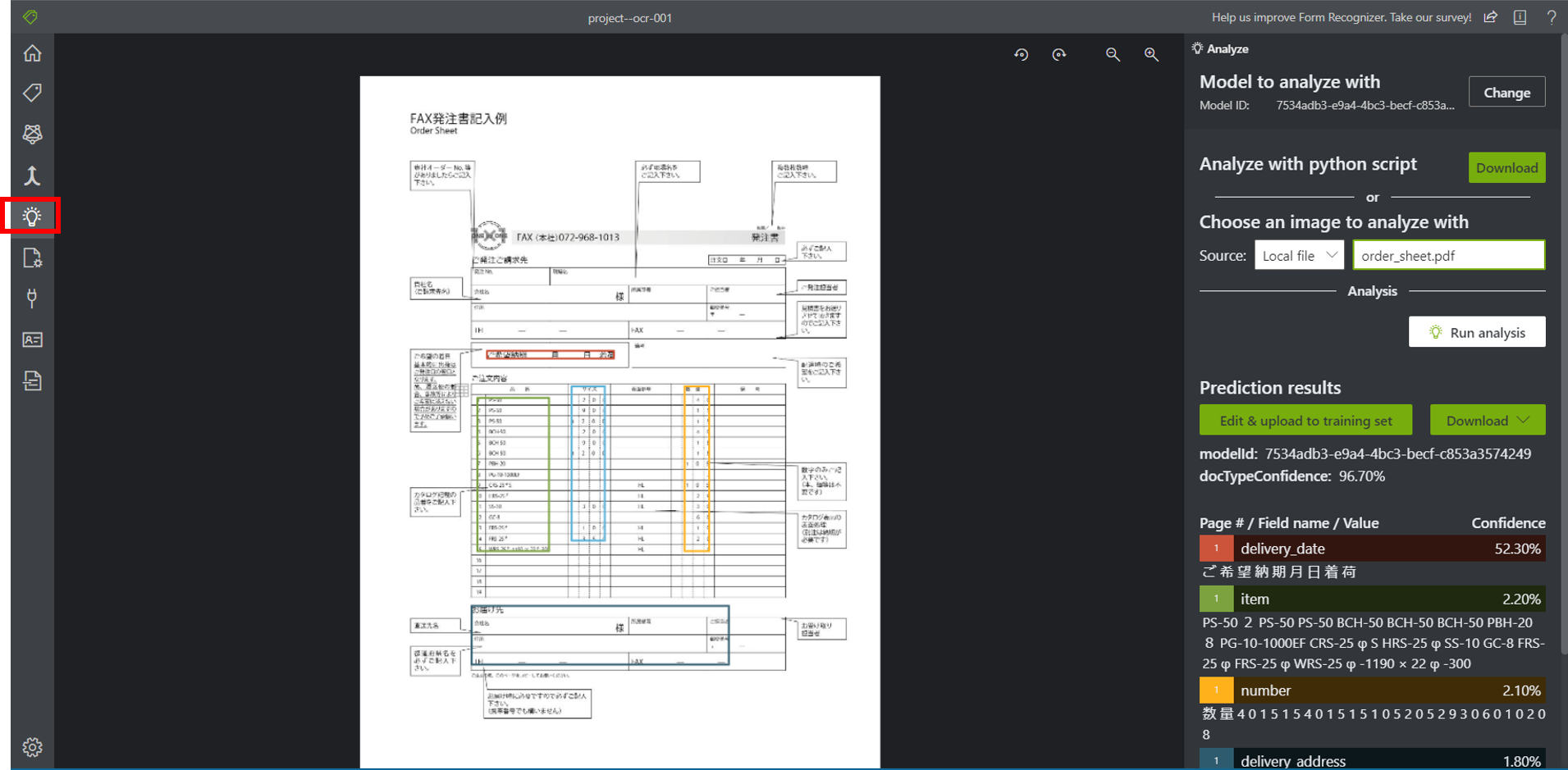
解析結果はJSONまたはCSV形式で出力することが可能です。
解析結果は以下の階層構造になっています。
テーブル情報が取得したければpageResultsのtables、ラベル付けした情報が取得したければdocumentResultsのfiledsから取得することができます。
status : succeeded
createdDateTime : yyyy-mm-ddThh:mm:ssZ
lastUpdatedDateTime : yyyy-mm-ddThh:mm:ssZ
analyzeResult : {5}
version : 2.1.0
errors
pageResults [n]
[0]
tables [n]
page : n
[0]
row
columns
boundingBox [8]
cells [n]
[0]
elements [n]:
[0] : #/readResults/0/lines/n/words/0
isHeader : true
rowIndex : 0
columnIndex : 0
text : ROW_ITEM
documentResults : [?]
[0]
pageRange : [n]
[0] : 1
[1] : 2
docTypeConfidence : n
modelId : 2e92a2c6-438e-45ae-acaa-9310db383b63
fileds : {n}
label_name-001 : {7}
text : hogehoge
type : string
valueString : hogehoge
page : 1
confidence : n
elements : [n]
[0] : #/readResults/0/lines/n/words/0
boundingBox [8]
readResults : [n]
[0] : {7}
angle : 0
height : n
width : n
page : n
unit : inch
lines : [n]
[0] : {4}
text : text-string
appearance : {1}
style {2}
confidence : n
name : other
words : [n]
[0] : {3}
boudingBox [8]
text : t
confidence : 1
selectionMarks [n]
[0] : {3}
boudingBox [8]
confidence : n
sate : selected
補足事項
- dockerコンテナをつかって、ローカル環境に上記と同じラベリングtoolをデプロイすることも可能です
- プレビュー版ですが、Form Recognizer Studioというモデル作成toolもあり、今後はこちらにシフトしていくものと思われます
参考ドキュメント
Rest API関連
https://docs.microsoft.com/ja-jp/rest/api/formrecognizer/
カスタムモデルのトレーニングセット作成
https://docs.microsoft.com/ja-jp/azure/applied-ai-services/form-recognizer/build-training-data-set
クォーター上限
https://docs.microsoft.com/en-us/azure/applied-ai-services/form-recognizer/service-limits
おわりに
この記事では、AzureのOCRサービス「Form Recoginzer」について紹介しました。
本記事が、OCRを学習するエンジニアの参考になれば幸いです。
お問合せフォーム