Azure AI Search入門
はじめに
この記事では、Azure AI Searchの基礎知識について紹介します。
Azure AI Searchとは
Azure AI Search(旧Azure Cognitive Search) は、ストレージ上のファイルなどのデータソースに対して、インデックスを作成し、作成したインデックスによる検索を可能にするサービスです。
インデックスには、ファイルの種類や、ファイルの作成日などのファイルに関するメタデータを格納することができ、 AI Searchを使うと、指定した種類に該当するファイルの絞り込みや、 指定した期間に該当する作成日のファイルの検索などが可能になります。
https://learn.microsoft.com/ja-JP/azure/search/search-what-is-azure-search
Azure AI Searchの基本要素
Azure AI Searchは以下の要素から構成されています。
- データソース
- インデクサー
- インデックス
- ドキュメント
- フィールド
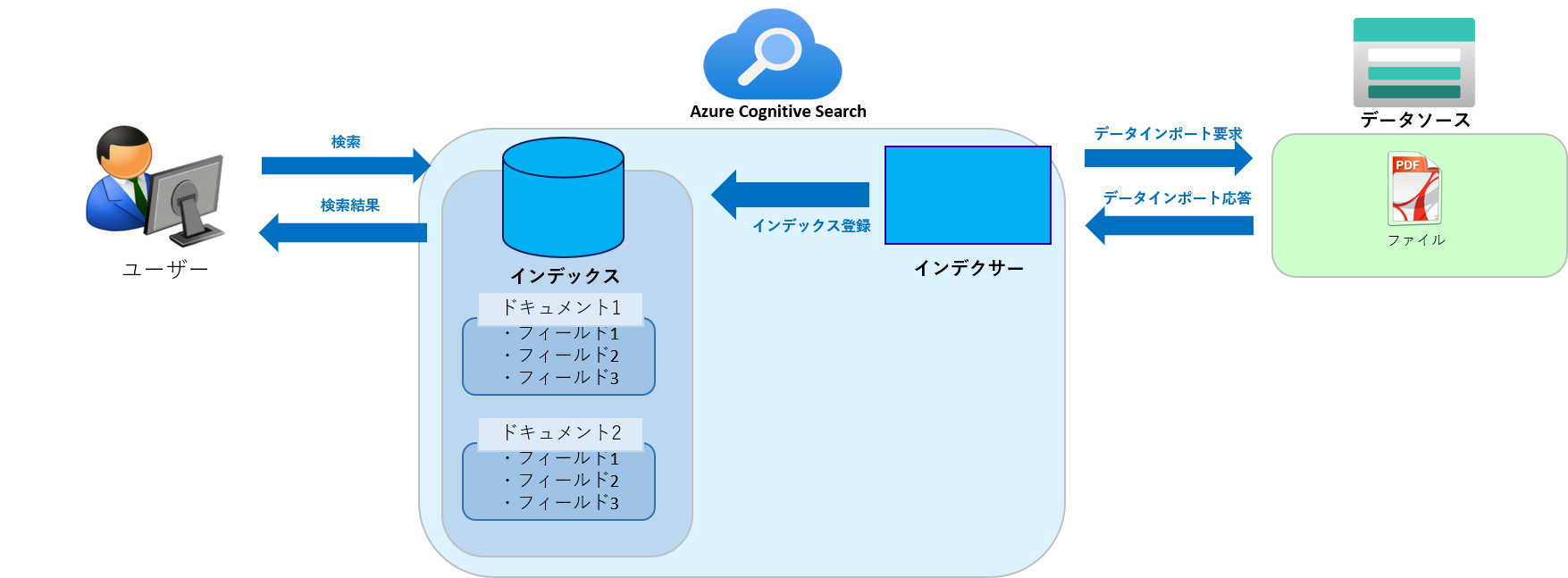
データソース
データソースはAzure AI Searchで検索対象となるデータが格納されている場所を指します。
具体例としては、Azure SQL Database、Azure Cosmos DB、Azure Blob Storageなどのデータストレージサービスが該当します。
インデクサー
インデクサーはデータソースからデータを読み取り、それをインデックスに格納する役割を持つものです。
インデックス
インデックスはデータソースから取得したデータを効率よく検索できる形式で格納したもののことです。
ドキュメント
ドキュメントはインデックス内で格納されているユニークな個々のレコードを指します。
各ドキュメントは一連のフィールドとその値から構成され、通常はJSONオブジェクトとして表現されます。
フィールド
フィールドはインデックス内の各ドキュメントが持つ属性を指します。
データベースでいうカラムに該当するものです。
Search Explorer
Search Explorerは、Azure portalからAzure AI Searchに検索クエリを実行することができる機能です。
Search Explorerは、AI Searchにインデックスを作成すると自動的に利用できるようになります。
Search Explorerを使うことで、クエリのテストや、インデックス内のドキュメントの確認をすることができます。
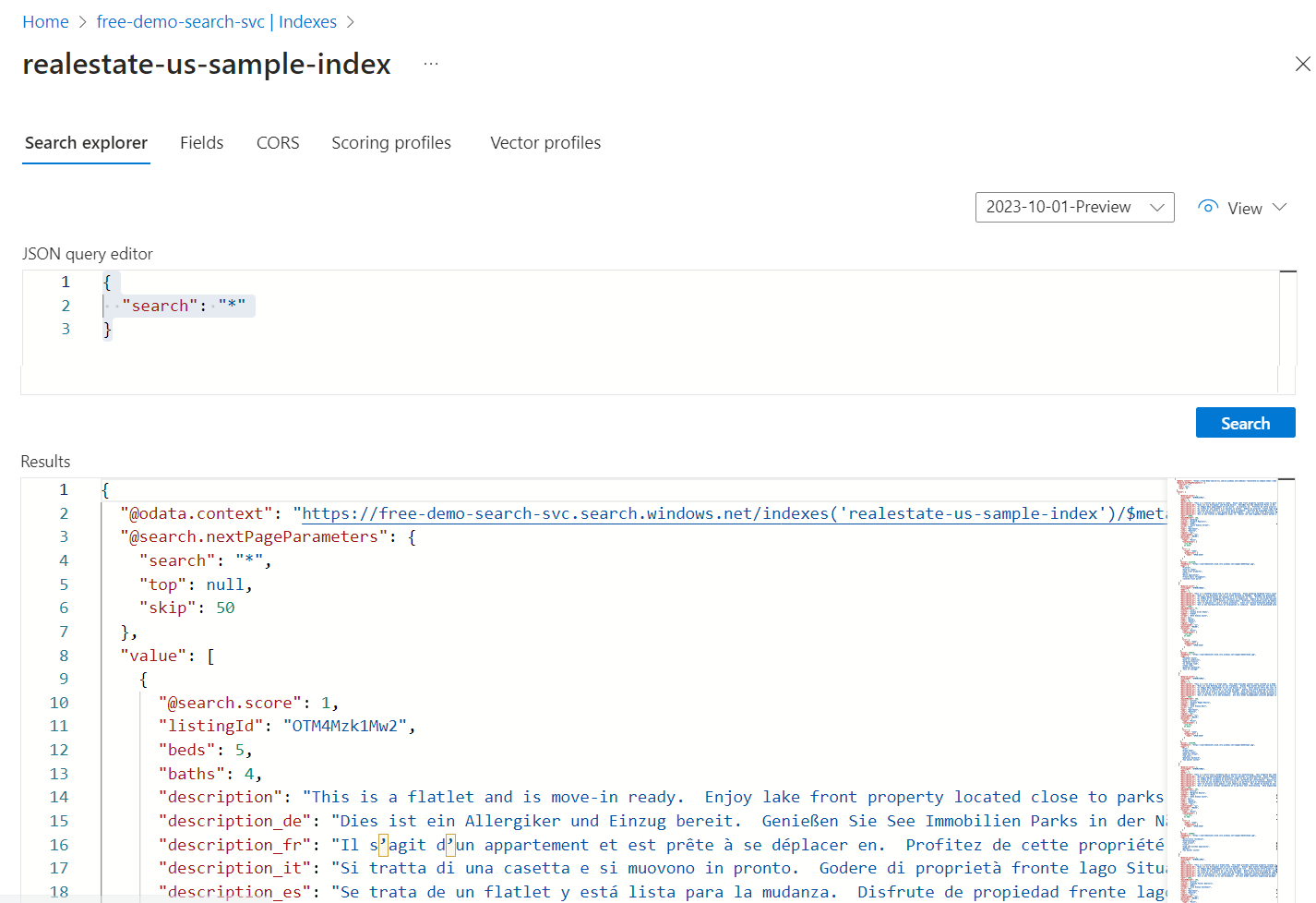
https://learn.microsoft.com/ja-jp/azure/search/search-explorer
検索の種類
Azure AI Searchでは以下のような様々な種類の検索をサポートしています。
- フルテキスト検索
- オートコンプリートとサジェスト
- 地理空間検索 : Geospatial Search
- フィルター検索
※ AI Searchでの検索をする際のクエリの例は以下の記事をご参照下さい。
フルテキスト検索
フルテキスト検索では、インデックス内のすべての “検索可能"に設定したフィールドをsearchで指定したキーワードで検索します。
一致する用語が見つかった場合、一致するドキュメントを関連性の順にランク付けし、応答の上位 50 (既定) を返します。
※topを指定した場合は別の番号を返します。
※ -でつながれた文字列または特殊文字に対するクエリでは、既定のStandard Lucene以外のアナライザーを使用してインデックスに正しいトークンが含まれていることを確認することが必要になります。
オートコンプリートとサジェスト
オートコンプリートやサジェスト(検索候補)は、ユーザーが、途中までの入力に基づいて完成する可能性のあるクエリフレーズを提案する機能です。
autocomplete と suggestions パラメーターは一緒に使用することも、個別に使用することもできますが、search と一緒に使用することはできません。
https://learn.microsoft.com/ja-jp/azure/search/search-add-autocomplete-suggestions
地理空間検索 : Geospatial Search
地理空間検索は、地理的な位置情報に基づいてデータを検索する方法を指します。
これは、特定の場所の関連するドキュメントの検索、または2つの位置間の距離を計算するなどに使用することができます。
地理的空間を使用するには、インデックスのフィールドを以下のいずれかの型でフィルター可能で定義し、経度と緯度を格納します。
- Edm.GeographyPoint
- Collection(Edm.GeographyPoint、Edm.GeographyPolygon)
フィルター検索
フィルター検索は、クエリの実行前にコンテンツを含めたり除外したりするための条件を指定して検索を行います。
Azure AI Searchのバックアップ・リストア
Azure AI Searchでは、バックアップ・リストアの機能は標準では提供されていません。
Azure Cognitive Search .NET サンプル リポジトリの index-backup-restore サンプルコードを使用して、インデックス定義とインデックス スナップショットを一連のJSONファイルにバックアップし、後で復元することができます。
https://learn.microsoft.com/ja-jp/azure/search/search-reliability#back-up-and-restore-alternatives
Azure AI Searchのアップグレード・ダウングレード
Azure AI Searchでは作成済みのリソースの価格レベルを後からアップグレード、ダウングレードすることはできません。
価格レベルをアップグレード、ダウングレードする場合、以下の手順が必要です。
- 新しい価格レベルでAI Searchを新規作成
- 既存のAI Searchから新しいAI Searchにインデックスなどの設定を移す
- 既存のAI Searchを削除する
https://learn.microsoft.com/ja-jp/azure/search/search-sku-tier#tier-upgrade-or-downgrade
Azure AI Searchのパーティションのスケーリング
Azure AI Searchにおいて、パフォーマンスに関連する概念として、レプリカとパーティションがあります。
レプリカとパーティションは、Azureポータルからスケーリングすることが可能です。
https://learn.microsoft.com/ja-jp/azure/search/search-capacity-planning
レプリカ
レプリカは、クエリ操作の負荷分散に使用されるSearchサービスのインスタンスです。
Azure AI Searchでは、レプリカを増やすことで、読み取りおよび検索のパフォーマンスを向上させることができます。
- 読み取りパフォーマンスの向上: 複数のレプリカがある場合、読み取りリクエストは各レプリカ間で負荷分散されます。
- 高可用性: 複数のレプリカがある場合、1つのレプリカが失敗しても、他のレプリカが引き続きサービスを提供できます。
パーティション
パーティションは、インデックスに対する読み取り/書き込み操作のための物理ストレージです。
AI Searchのインデックス内のデータは複数のパーティションに分割して保持することができ、各パーティションは独立して書き込み操作を処理するため、書き込みパフォーマンスが向上します。
注意事項
ADLS利用時のタイムスタンプ変更警告の発生
This ADLS Gen2 indexer maps the property 'metadata_storage_path' to the index key, which may not reindex documents if directories are renamed.
この警告は、ADLS Gen2を使用している場合、ドキュメントキーやディレクトリ名、パスを変更すると、インデクサがどのコンテンツがインデックスされたか、そして最後にインデックスされたのはいつかを知るために使用する内部追跡情報が壊れてしまいます。
このため、ドキュメントキーやディレクトリ名、パスを変更した場合にディレクトリ内のすべてのblobのLastModifiedタイムスタンプを更新するように促す警告メッセージが出る。
インデクサーの実行のたびに警告がでるが、基本的に問題はない。
サイズが大きいフィールドはソート、ファセット、フィルタの対象外にしたほうがいい
contentなどの格納されるテキストのサイズが大きいフィールドをソート、ファセット、フィルタに設定しているといかのようなエラーが発生することがあります。
Field 'content' contains a term that is too large to process.
The max length for UTF-8 encoded terms is 32766 bytes.
The most likely cause of this error is that filtering, sorting,
and/or faceting are enabled on this field, which causes the entire field value to be indexed as a single term.
Please avoid the use of these options for large fields.
フィルタリング、ソート、ファセットが有効になっていると、フィールド値全体が1つの用語としてインデックス化されるため、無効になっている場合よりAzure AI Searchのストレージを4倍近く使用する可能性があり、 上限値を超過すると上記のようなエラーが発生します。
サイズが大きいフィールドはソート、ファセット、フィルタの対象外にしたほうがいいでしょう。
https://learn.microsoft.com/ja-jp/azure/search/search-performance-tips
https://learn.microsoft.com/ja-jp/azure/search/search-limits-quotas-capacity
AI Searchの言語アナライザーは適切な言語に設定しないと意図しない検索結果になる
AI Searchの個々のフィールドには解析を行う言語アナライザーを指定することができます。
フィールドの値が日本語であれば、日本語用の言語アナライザーを指定する必要があるのですが、言語アナライザーに適切なアナライザーが設定されていないと検索結果が意図しないものになる可能性があります。
https://jpazpaas.github.io/blog/2023/06/20/cognitive-search-unexpected-search-results.html
プライベートエンドポイントと接続する場合はS2以上のプランにする必要がある
プライベートエンドポイントと接続する場合は、Azure AI SearchはS2以上にする必要があります。
2023/09/30時点でS2の場合は¥259.58/時間で1ヶ月あたり、
259.58 * 24 * 30 = 約18万6897円かかります。`
https://azure.microsoft.com/ja-jp/pricing/details/search/#pricing
おわりに
この記事では、Azureの「Azure AI Search」について紹介しました。
本記事が、Azure AI Searchを学習するエンジニアの参考になれば幸いです。
お問合せフォーム