はじめに
この記事では、Azure、AWS、Google Cloudの3大クラウドサービスのAIサービスの新規機能リリース履歴をまとめています。
主に以下のURLの情報をもとに新機能のキャッチアップを行っています。
Azure
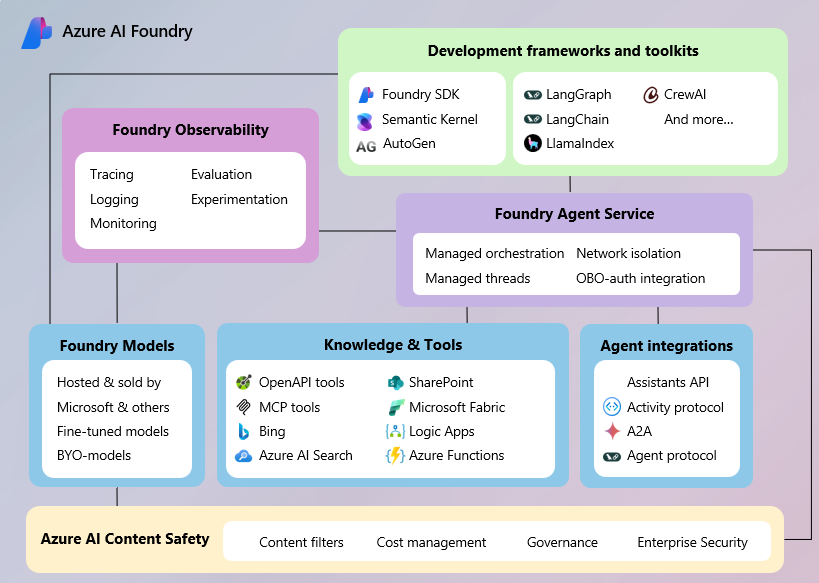
2025年05月20日: Azure AI Foundry Agent Serviceの一般提供が開始
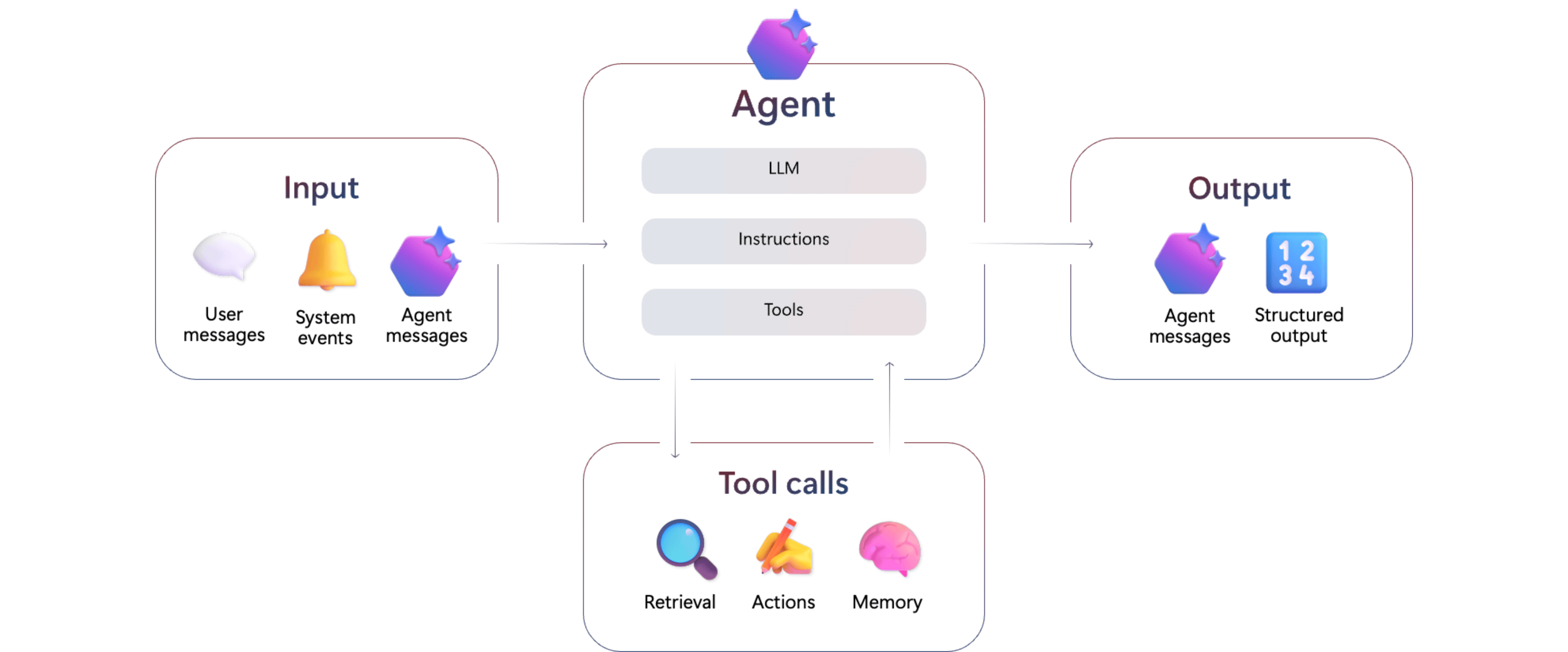
Azure AI Agent Serviceは、AI エージェントの構築・管理ができるマネージドサービスです。
Azure AI Agent Serviceは、以下のような機能を持ちます。
- AI Foundry PortalやAzure AI Foundry SDKを使って、エージェントの構築、管理が可能
- 複数のAIエージェントを組み合わせるマルチエージェントの構築が可能
- A2A(Agent2Agent)、MCP(Model Context Protocol) などの業界標準プロトコルをサポート
モデル料金
- モデルの利用料金はAzure OpenAI Serviceの価格表とモデルカタログに従う
ツール料金
| サービス | 料金 | 備考 |
|---|---|---|
| ファイル検索ストレージ | $0.10/GB/日 | 1GBまで無料 |
| コードインタープリタ | $0.03/セッション | |
| Computer Use入力トークン | $3/1Mトークン | Computer use使用量料 |
| Computer Use出力トークン | $12/1Mトークン | Computer use使用量料 |
Microsoft Fabric、Microsoft SharePoint、Grounding with Bing Search、Azure AI Search、およびユーザーが独自に持ち込むナレッジ接続については、別途料金とライセンスが発生します。 さらに、Azure Logic AppsやAzure Functionsなど、現在利用可能な自動化ツールや今後追加される自動化ツールについても料金が発生します。
クォーター制限
| 制限名 | 上限値 |
|---|---|
| エージェント/スレッドごとの最大ファイル数 | 10,000 |
| エージェント・ファインチューニング用の最大ファイルサイズ | 512 MB |
| エージェント用アップロードファイル全体の最大容量 | 200 GB |
| エージェントのトークン上限 | 2Mトークン |
- Azure公式ドキュメント: Azure AI Foundry Agent Serviceとは
- Azure公式ドキュメント: Azure AI Foundry
- Azure公式ドキュメント: Azure AI Foundry Agent Service のクォータと制限
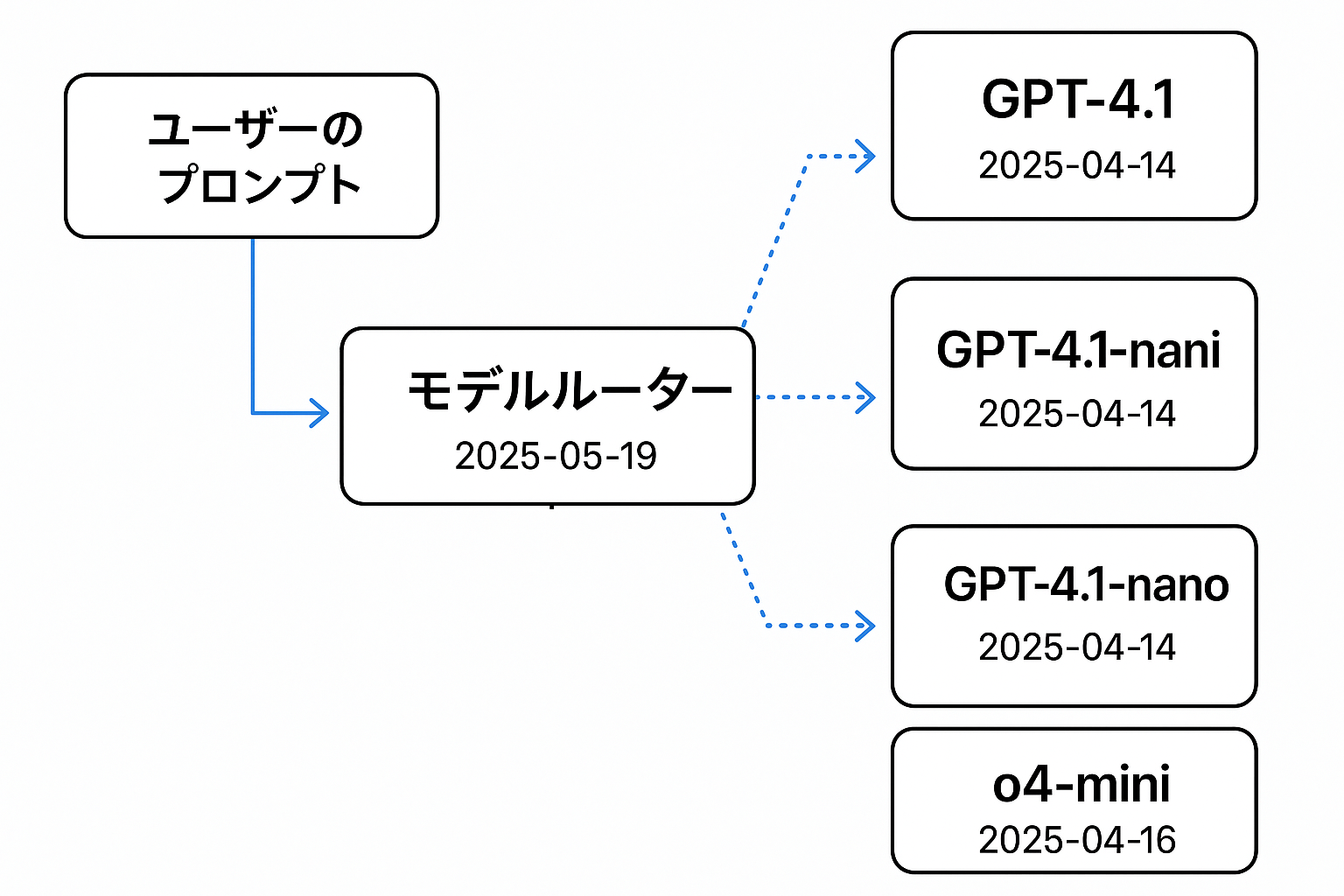
2025年05月20日: Model Router(プレビュー)が提供開始
Azure AI Foundryに最適なチャットモデルを自動選択するモデルルーターの機能が追加されました。
Azure AI Foundry のモデル ルーターは、デプロイ可能な AI チャット モデルであり、特定のプロンプトにリアルタイムで応答する最適な大規模言語モデル (LLM) を選択するようにトレーニングされています。
プロンプトに最適なモデルを選んで応答精度の向上を可能します。
モデルルーターのバージョン
- 2025-05-19
ファウンディングモデル (バージョン)
- GPT-4.1 (2025-04-14)
- GPT-4.1-mini (2025-04-14)
- GPT-4.1-nano (2025-04-14)
- o4-mini (2025-04-16)
モデルルーターを使用しても、課金対象は選択されたファウンディングモデルのみであり、ルーティング機能自体には追加料金はかかりません。
2025年5月20日: Spotlighting for Prompt Shieldsが提供開始
Prompt Shields(プロンプト保護機能)は、Azure OpenAIのContents filterの機能の一部で、ユーザーによるプロンプト攻撃を検出・防止する仕組みです。
Prompt Shieldsにプロンプト内のテキストに対し「信頼度が低い」ことをモデルに伝えるSpotlighting機能が導入されました。
Spotlightingは入力ドキュメントに特殊なフォーマットでタグ付けすることで、モデルに対する信頼度が低いことを示し、 間接攻撃に対する保護を強化する機能です。
デフォルトでは無効ですが、Azure PortalやAPIで有効化可能です。
Spotlightingが有効になっていると、Base64エンコーディングでプロンプト内のテキストを変換します。
Base64変換されたことにより、モデルがこのプロンプトを直接のユーザーおよびシステムプロンプトよりも信頼性が低いものとして扱うように認識されるようになります。
これにより、プロンプトにある意図しないコマンドやアクションをモデルが実行するのを防ぐことができます。
スポットライトに直接コストはかかりませんが、ユーザーのプロンプトにトークンが追加されるため、総コストが増加する可能性があります。
また、スポットライトを当てると、長い文書が入力サイズの制限を超える可能性があることにも注意が必要です。
2025年05月20日: Personally identifiable information (PII) filterが提供開始
氏名、住所、電話番号、メールアドレス、マイナンバー、運転免許証番号などの個人を特定できる情報を自動検出する機能です。
これにより、個人情報の漏洩や不正利用(例:なりすまし、詐欺)を防止します。
-
主な機能
- LLM出力を自動スキャンし、個人情報を検出
- 該当情報はフラグ付けまたは出力ブロックが可能
- 対象とするPIIの種類は設定可能[Azure AI Languageドキュメントに準拠](https://learn.microsoft.com/en-us/azure/ai-services/language-service/personally-identifiable-information/concepts/entity-categories)
-
2種類のフィルターモード
- Annotate(注釈)モード→ PIIが含まれる出力にフラグを付ける
- Annotate Block(注釈+ブロック)モード→ PIIが含まれる場合、出力全体をブロック
2025年05月28日: 動画生成モデル「Sora」がプレビュー提供開始
動画生成モデル「Sora」がリリースされました (プレビュー)。
Sora(2025-05-02)は、テキストの指示からリアルで想像力豊かなビデオシーンを作成できるOpenAIのビデオ生成モデルです。
動作概要
- ジョブ作成:テキストプロンプトと動画の仕様(解像度、長さなど)を指定してジョブを作成。
- 非同期処理:ジョブはバックグラウンドで処理され、ステータスをポーリングして進行状況を確認。
- 動画取得:ジョブが完了すると、生成された動画をダウンロード可能。
制限事項
- 解像度:480x480、720x720、1080x1080など、特定の解像度に対応。
- 動画の長さ:1秒から20秒まで。
- 同時ジョブ数:最大2つのジョブを同時に実行可能。
- ジョブの有効期限:ジョブは作成から24時間以内に完了する必要がある。
- コンテンツフィルタリング:暴力的なシーンは生成されず、関連するコンテンツも制限される。
- 技術的制限:複雑な物理現象や因果関係、空間的推論、時間的なイベントの正確なシーケンスには制限がある。
プロンプトのベストプラクティス
-
言語:英語またはラテン文字を使用することで、最適な動画生成が可能。
AWS
2025年05月12日: AWS BedrockのカスタムモデルにQwen2, Qwen2.5, Qwen2-VL, Qwen2.5-VLが追加
AWS BedrockのカスタムモデルにQwen2, Qwen2.5, Qwen2-VL, Qwen2.5-VLが追加されました。
Amazon Bedrock では、Amazon Bedrock カスタムモデルインポート機能を使用して、Amazon SageMaker AI など他の環境でカスタマイズしたファウンデーションモデルをインポートすることで、カスタムモデルを作成できます。
2025年05月12日: AWS 管理ポリシーに新しい権限「AmazonBedrockFullAccess 」が追加
AmazonBedrockFullAccessがAWS 管理ポリシーの新しい権限として追加されました。
AWS公式: AWS managed policies for Amazon Bedrock
2025年5月13日: Amazon Bedrock Guardrails がクロスリージョン推論をサポート
Amazon Bedrock Guardrails がクロスリージョン推論をサポートするようになりました。
AWS公式: Guardrailsの推論をAWSリージョンに分散させる
2025年5月16日: BDAが動画用ブループリントをサポート
Amazon Bedrock Data automation(以後、BDA)とは、ドキュメント、画像、ビデオ、オーディオなどの非構造化なコンテンツから、生成 AI を活用して構造化形式などに変換するサービスです。
今回の改定でBDAが動画ブループリント対応しました。
ブループリントとは、「どうやって動画や自動で分析・整理するか」を決める設計図のこと。 動画から「どんな情報を抽出したいか」をブループリントで指定します。
-
動画向けのブループリントでは、「粒度(granularity)」という設定があり、2つのタイプがある
-
動画全体(Video) 動画全体について一つの答えを出す。例:動画全体の要約がほしいときは「Video」に設定。
-
チャプターごと(Chapter) 動画の区切り(チャプター)ごとに答えを出す。例:各チャプターの内容をそれぞれ要約したいときは「Chapter」に設定。
-
-
定義例(JSONイメージ)
"key-visual-objects": {
"items": { "$ref": "bedrock-data-automation#/definitions/Entity" },
"type": "array",
"instruction": "動画内で目立つオブジェクトを検出してください",
"granularity": [ "chapter" ]
}
2025年5月22日: Amazon BedrockでClaude Sonnet 4およびClaude Opus 4が利用可能に
5/22にAntropicから提供されたClaude Sonnet 4および、Claude Opus 4がBedrockで利用可能になりました。
-
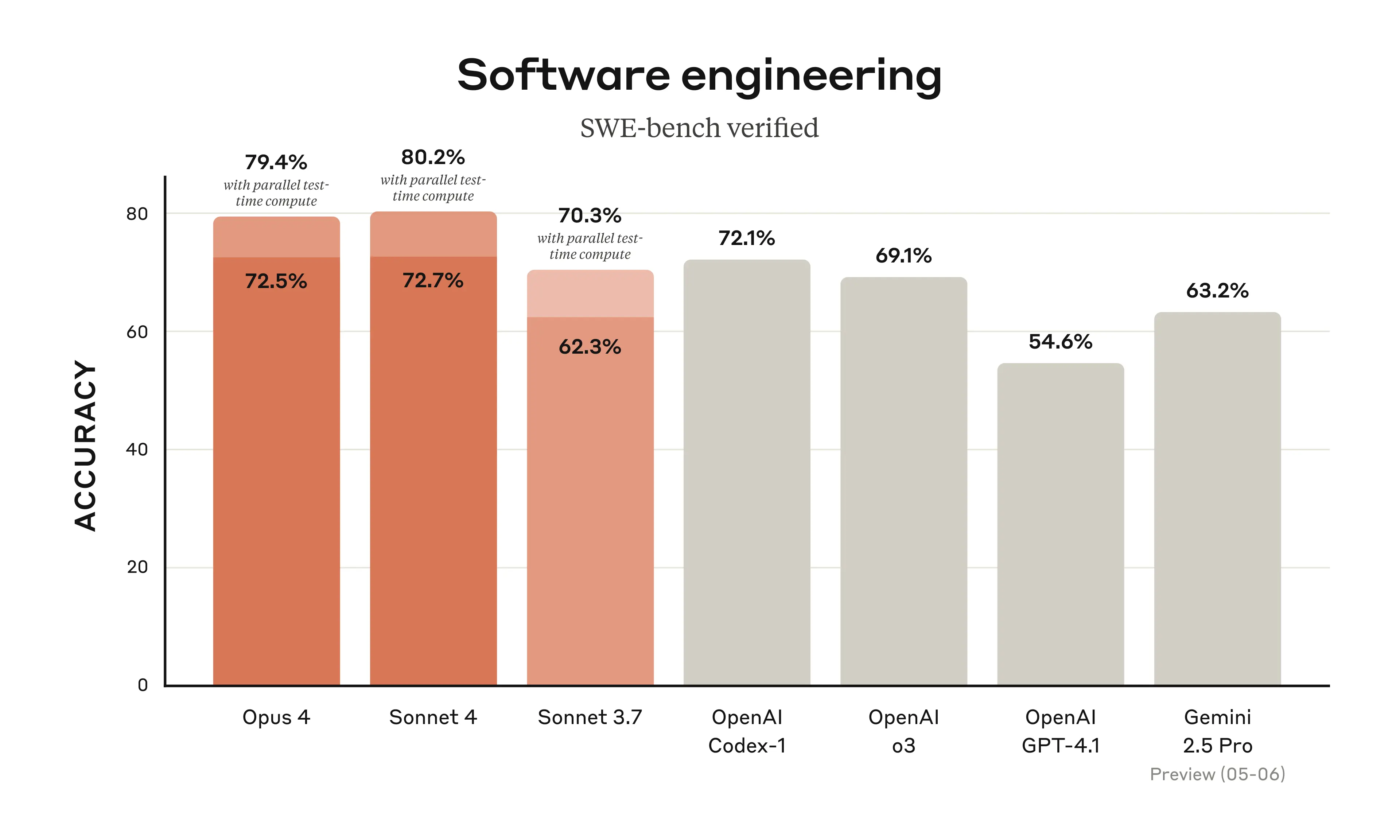
Claude Sonnet 4はClaude Sonnet 3.7より全体的に性能アップ
-
特にコーディング能力が向上
- SWE-bench Verified: Opus 4は72.5%、Sonnet 4は72.7%というトップクラスのスコアを記録。
- Terminal Bench: Opus 4は43.2%のスコア。
-
大容量のコンテキスト(20万トークン)
-
Sonnet 3.7と同様に即時応答と拡張思考モードの2つのモードを持つハイブリッド推論モデル
- 拡張思考モード時の推論プロセスは Sonnet 3.7など完全出力でしたが、Claude 4では要約されたものが出力されるようになってます
- 完全出力が必要な場合は、AntropicまたはAmazon、Googleなどのベンダーのセールチームに問合せが必要です
-
インターリーブ思考をサポート
- ツールの利用など、外部情報を取得する「行動」と、「考える」推論プロセスを交互に進めるAIの思考法。
- ツール呼び出しの「前後」に推論(思考)を挟み、得た中間結果を踏まえ、次の行動や推論を柔軟に変える
| モデル名 | 特徴 | コンテキストウィンドウ | 入力トークン[/1M] | 出力トークン[/1M] | プロンプトキャッシュ書込 | プロンプトキャッシュ読込 |
|---|---|---|---|---|---|---|
| Claude Opus 4 | 複雑なタスク向け最高知能 | 200K | $15 | $75 | $18.75 | $1.50 |
| Claude Sonnet 4 | 知能・コスト・速度の最適バランス | 200K | $3 | $15 | $3.75 | $0.30 |
- Anthropic公式ドキュメント: Claude 4
- Anthropic公式ドキュメント: API価格
- Anthropic公式ドキュメント: 拡張思考
- AWS公式ドキュメント: サポートモデル
- AWS公式ドキュメント: 拡張思考
2025年5月28日: シンプルなAmazon Bedrockエージェント作成のためのチュートリアルを追加
Amazon Bedrockエージェント作成のためのチュートリアルドキュメントが追加されました。
Google クラウド
2025年05月02日: Vertex AIのグローバルエンドポイントがGA
Vertex AI v1でグローバルエンドポイントが一般提供(GA)となりました。
グローバルエンドポイントはAzure OpenAIのグローバルデプロイメントに該当する機能で、使用すると、全体的な可用性が向上し、リソース枯渇(429エラー)を減らすことができます。
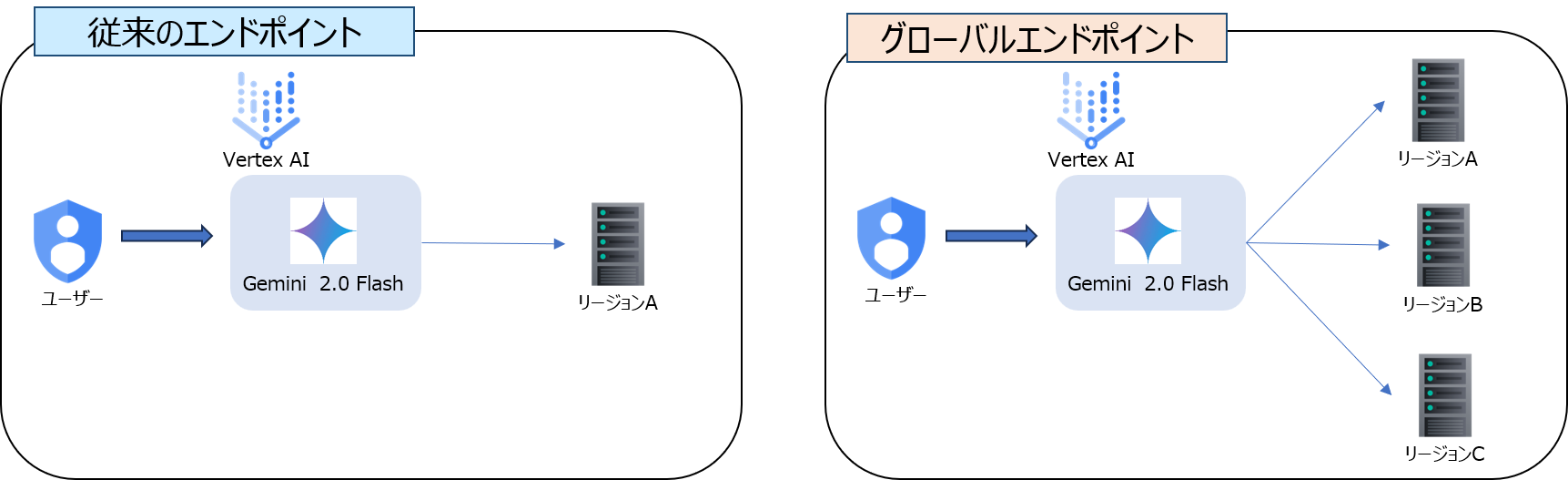
グローバルエンドポイントは以下のモデルで対応:
- Gemini 2.0 Flash(Live API対応)
- Gemini 2.5 Pro
- Gemini 2.5 Flash
- Gemini 2.0 Flash
- Gemini 2.0 Flash-Lite
グローバルエンドポイントの使用方法は、リソースのロケーションを global に設定します。
https://aiplatform.googleapis.com/v1/projects/test-project/locations/global/publishers/google/models/gemini-2.0-flash-001:generateContent
Google Gen AI SDKで使用する場合は、次のようにクライアントを作成します。
client = genai.Client(
vertexai=True, project='your-project-id', location='global'
)
グローバルエンドポイント使用時に利用できない機能は以下の通り。
-
チューニング(モデルの調整)
-
バッチ予測
-
コンテキストキャッシュ
-
RAG(検索拡張生成)のコーパス(ただしRAGリクエスト自体は可能)
-
プロビジョンド・スループット(固定リソース割当)
2025年05月05日: Vertex AIでユーザー独自データを使ったGrounding機能がGA
Vertex AIの「Grounding」は、生成AIモデルの出力を信頼できる情報源に結びつけ、回答時に出典が明記したレスポンスを生成する機能です。
以下の2種類のGroundingが可能です。
-
Google 検索によるGrounding
-
ユーザー独自データでのGrounding(プレビュー)
ユーザー独自データでのGroundingについての以下の機能が一般提供(GA)となりました。
2025年05月07日: Gemini 2.0 Flashに画像生成に対応したモデルがパブリックプレビュー
Gemini 2.0 Flashに画像生成機能に対応したモデル: gemini-2.0-flash-preview-image-generationがリリースされました。
このモデルを使用することでテキストだけでなく、画像の出力も可能になります。
2025年05月14日: MedLMが2025年9月29日に廃止予定
MedLMが非推奨となり、2025年9月29日以降、アクセス不可になります。
MedLM は、医療業界向けに微調整された基盤モデルファミリーです。
2025年05月15日: Vertex AIのアクセラレーターのサポート対象追加
Vertex AI のアクセラレーターは、Google クラウド 上で機械学習モデルのトレーニングや推論を高速化するための専用ハードウェア(GPU や TPU)を指します。
以下がそれぞれ追加されています。
- A3 Ultra:高性能な GPU を搭載し、大規模なディープラーニングモデルのトレーニングに最適。
- A4:バランスの取れた性能で、さまざまなトレーニングニーズに対応。
- A3 Mega:高速な推論処理が可能で、リアルタイムアプリケーションに適している。
- A4:トレーニングと同様に、推論処理でもバランスの取れた性能を提供。
2025年5月20日: Vertex AI Agent Engineの機能改善
-
デプロイ済みエージェントをコンソールから管理できるようになりました。(プレビュー機能)
-
Agent Development Kitエージェントでセッションサポート追加されました。
-
Google Cloud公式ドキュメント: デプロイ済みエージェントをコンソールから管理できるようになった(プレビュー機能)
-
Google Cloud公式ドキュメント: Agent Development Kitエージェントでセッションサポート追加
2025年5月20日: Gemini 2.5 Flashの新しいモデルバージョン「gemini-2.5-flash-preview-5-20」がリリース
Gemini 2.5 Flashのモデルバージョンが初期の2025-04-17バージョンからgemini-2.5-flash-preview-5-20にアップデートされました。
2025年5月20日: Gemini 2.5 Flash with Live APIのAudio-to-Audioサポートがプライベートプレビュー
Gemini 2.5 Flash with Live APIのAudio-to-Audioサポートがプライベートプレビューとして利用可能になりました。
この新機能を使用するには、ユーザーを許可リストに登録する必要があります。
2025年5月20日: MedgemnaがModel Gardenで利用可能に
MedGemmaは、医療テキストや医療画像の理解に特化して訓練されたGemma 3モデル群。
開発者はMedGemmaを使うことで、医療分野向けAIアプリケーションの開発を加速できる。
現在、MedGemmaには以下の2種類が存在する:
-
4Bマルチモーダル版(テキスト+画像対応)
-
27Bテキスト専用版(テキストのみ対応)
2025年5月20日: Gemini 2.5 Pro / Flashで思考要約(thought summaries)を実験機能として追加
Gemini 2.5 Proおよび2.5 Flashの実験的機能として、思考要約が利用可能になりました。
2025年5月20日: 最新の音楽世代モデル「Lyria 2」が一般提供開始されました
Googleの最新の音楽生成モデルである Lyria 2 が、現在一般提供開始されました。
2025年5月20日: Imagen 4のプレビュー版(05-20)とUltra Generate Experimental(05-20)を提供開始
Imagen 4のプレビュー版(05-20)とUltra Generate Experimental(05-20)を提供開始されました。
2025年5月20日: 動画生成AI「Veo 3」のプレビュー提供開始
Veo 3(動画生成AI)がプレビューで提供開始(限定ユーザーのみ)されました。
2025年5月22日: VertexAIでClaude Sonnet 4およびClaude Opus 4が利用可能に
5/22にAntropicから提供されたClaude Sonnet 4および、Claude Opus 4がVerteAIで利用可能になりました。
-
Claude Sonnet 4はClaude Sonnet 3.7より全体的に性能アップ
-
特にコーディング能力が向上
- SWE-bench Verified: Opus 4は72.5%、Sonnet 4は72.7%というトップクラスのスコアを記録。
- Terminal Bench: Opus 4は43.2%のスコア。
-
大容量のコンテキスト(20万トークン)
-
Sonnet 3.7と同様に即時応答と拡張思考モードの2つのモードを持つハイブリッド推論モデル
- 拡張思考モード時の推論プロセスは Sonnet 3.7など完全出力でしたが、Claude 4では要約されたものが出力されるようになってます
- 完全出力が必要な場合は、AntropicまたはAmazon、Googleなどのベンダーのセールチームに問合せが必要です
-
インターリーブ思考をサポート
- ツールの利用など、外部情報を取得する「行動」と、「考える」推論プロセスを交互に進めるAIの思考法。
- ツール呼び出しの「前後」に推論(思考)を挟み、得た中間結果を踏まえ、次の行動や推論を柔軟に変える
| モデル名 | 特徴 | コンテキストウィンドウ | 入力トークン[/1M] | 出力トークン[/1M] | プロンプトキャッシュ書込 | プロンプトキャッシュ読込 |
|---|---|---|---|---|---|---|
| Claude Opus 4 | 複雑なタスク向け最高知能 | 200K | $15 | $75 | $18.75 | $1.50 |
| Claude Sonnet 4 | 知能・コスト・速度の最適バランス | 200K | $3 | $15 | $3.75 | $0.30 |