Azure AI Document Intelligence入門
はじめに
Microsoft Azureには、画像からテキストを抽出するOCRの機能を持ったサービス「Azure Form Recognizer」というサービスがあったのですが、2023年7月に名称変更して「Azure AI Document Intelligence」というサービス名に変更になりました。
「Azure Form Recognizer」については、以前からこちらの記事で紹介していますが、今回の名称変更を受けて、改めて「Azure AI Document Inteljence」について紹介します。
Azure AI Servicesとは
Azure AI Serviceは、事前構築済みのAIモデルを利用することができるAzureのAI系のサービスの総称です。
Azure AI Serviceには以前Cognitive Services および Azure Applied AI Services と呼ばれていたものすべてが含まれています。

https://learn.microsoft.com/ja-jp/azure/ai-services/what-are-ai-services
Azure Document IntelligenceもAzure AI Servicesの一つです。
Azure Document Intelligenceとは
Azure Document Intelligenceとは、請求書、レシート、名刺などのドキュメントから文字情報を取得するOCR機能の一つです。
Azure Document IntelligenceのAPIを実行すると、リクエスト時で渡されたPDFファイルなどのドキュメントのURLを解析し、解析したテキスト情報をHTTPレスポンスとして返します。

https://docs.microsoft.com/ja-jp/azure/applied-ai-services/form-recognizer/
https://azure.microsoft.com/ja-jp/products/ai-services/ai-document-intelligence
Azure Document Intelligenceの機能
Azure Document Intelligenceは次の機能を持っています。
- ドキュメント分析モデル
- 事前構築済みモデル
- カスタムモデル
ドキュメント分析モデル(Document analysis model)
ドキュメント分析モデルはドキュメントから、テキストや、テーブルの構造、テキスト、テキストのバウンディングボックスの座標(位置情報)などをドキュメントから抽出します。
事前構築済みモデル(Prebuilt model)
事前構築済みモデルは請求書、レシート、名刺などMicrosoftが事前に用意している特定のドキュメント専用のAIモデルを使用して、フォームを解析する機能です。
カスタムモデル
カスタムモデルは、ユーザが独自に作成することができるAIモデルです。
事前構築済みモデルに用意されていないオリジナルのフォームを解析する場合は、カスタムモデルが必要です。
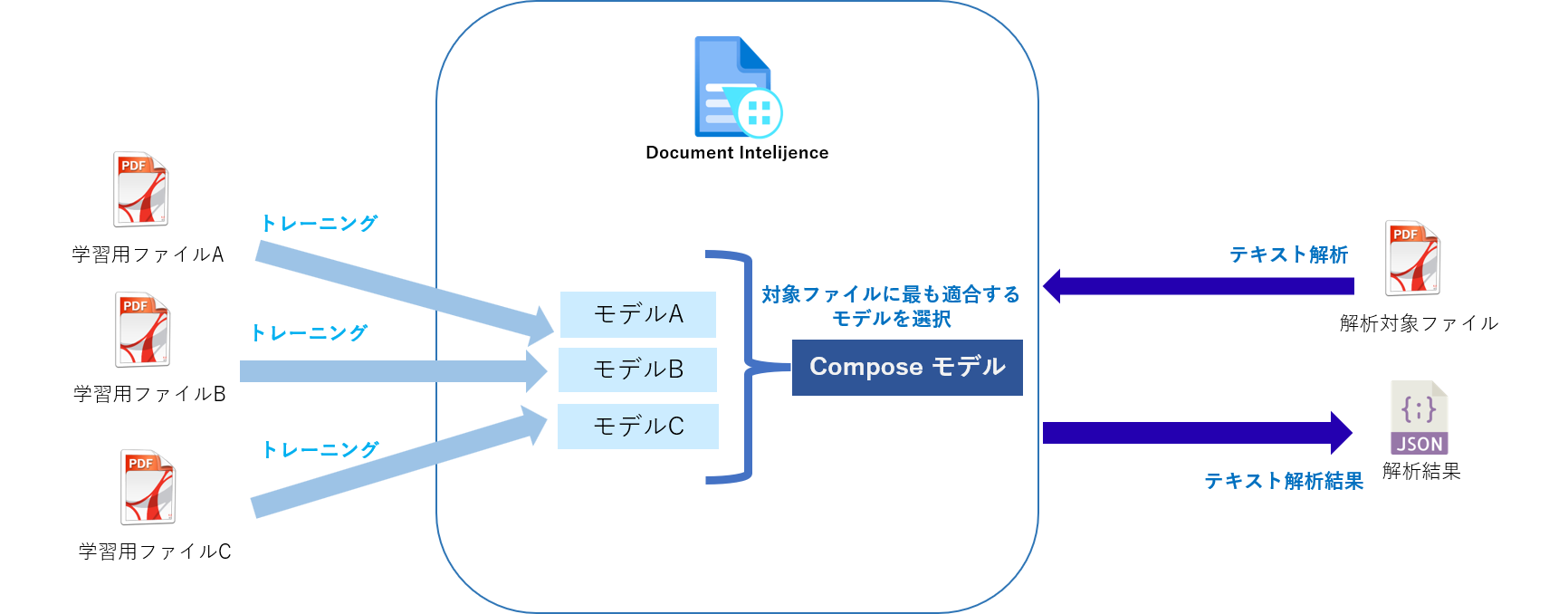
Composeモデル(複合モデル)
Composeモデルは複数のカスタムモデルを組み合わせたモデルです。
Composeモデルに対してテキスト解析要求を実行すると、設定したカスタムモデルの中から要求を受けたファイルが最も適合する割り当てモデルを選択し、そのモデルの結果を返します。
最大100個の学習済みカスタムモデルを1つのComposeモデルに割り当てることができます。
https://westus.dev.cognitive.microsoft.com/docs/services/form-recognizer-api-v2-1/operations/Compose
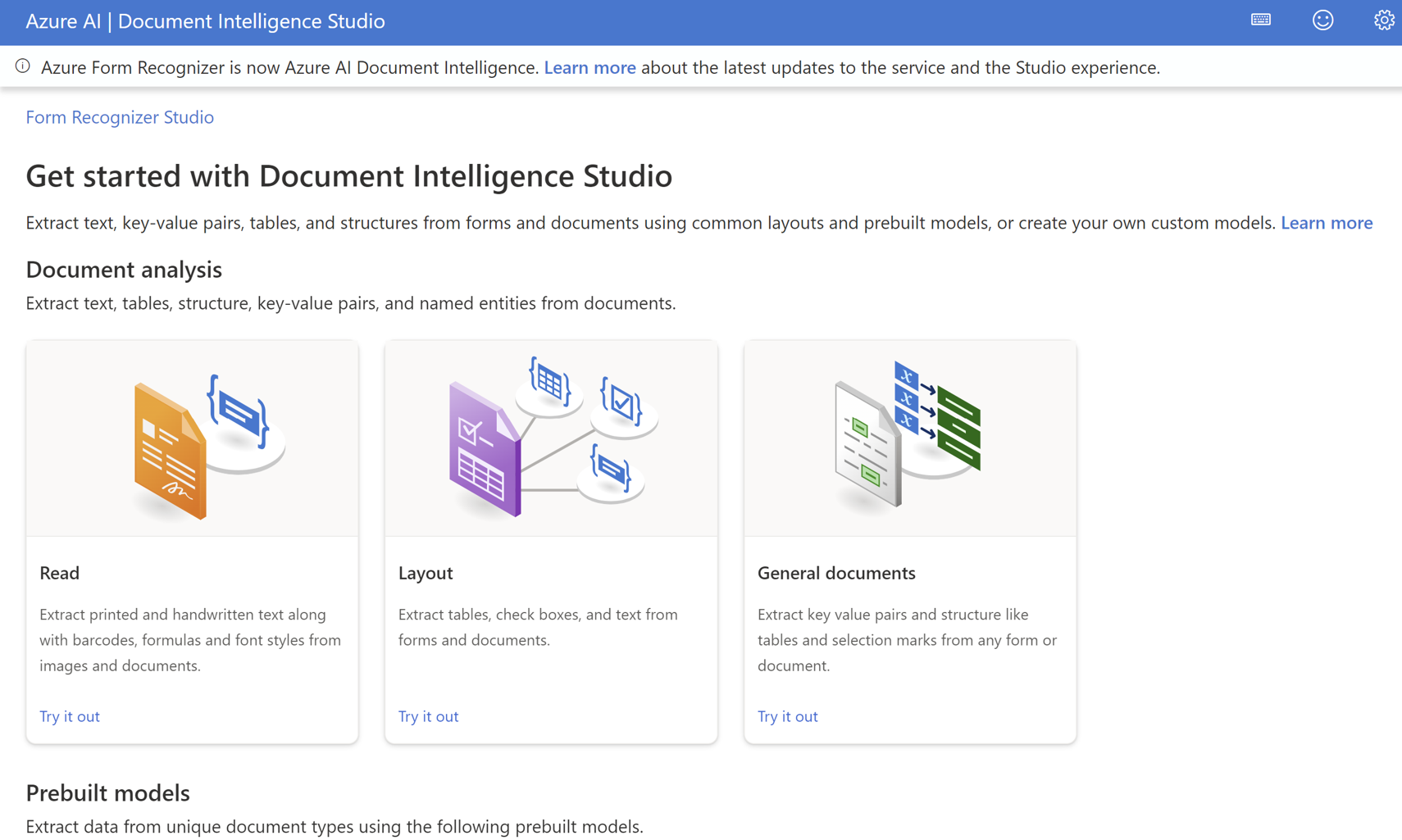
Azure Document Intelligence Studioから操作
Document IntelligenceはAzureポータルでDocument Intelligenceのリソースの作成後、 Azure Document Intelligence Studioにアクセスすることで、利用することができるようになります。
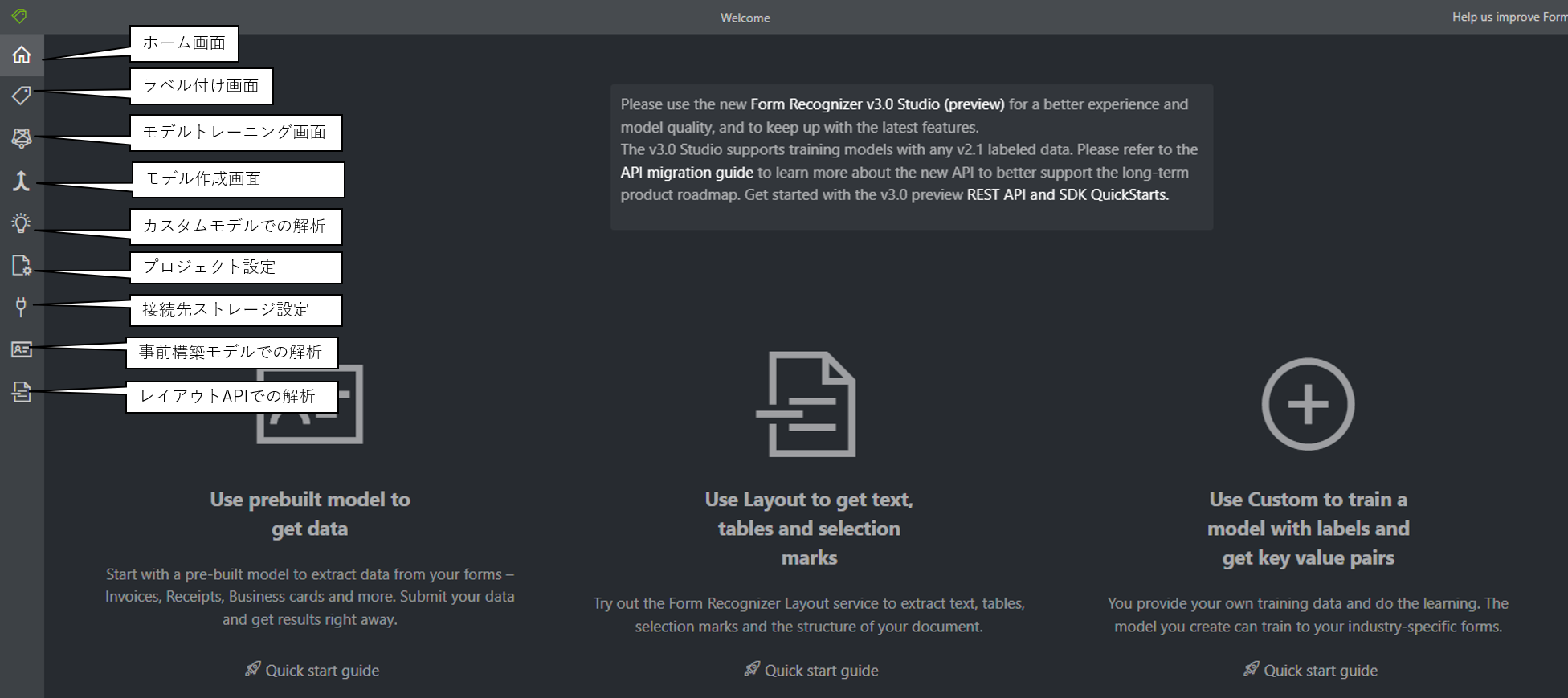
余談ですが、旧サービスのForm Recognizerの初期のときは、以下のWEB UIを使用していました。
この当たりは名称変更とともに改善された点になるかと思います。
https://fott-2-1.azurewebsites.net/layout-analyze
https://qiita.com/komiyasa/items/afee82f7baddcd820251
Document analysisを操作
Document analysisは以下の3つのAPIを使用することができます。
- Read API
- Layout API
- General API
Readを使用する
Readはドキュメントからテキスト情報を読取る機能です。
以下の手順書で使用することができます。
- Readをクリック
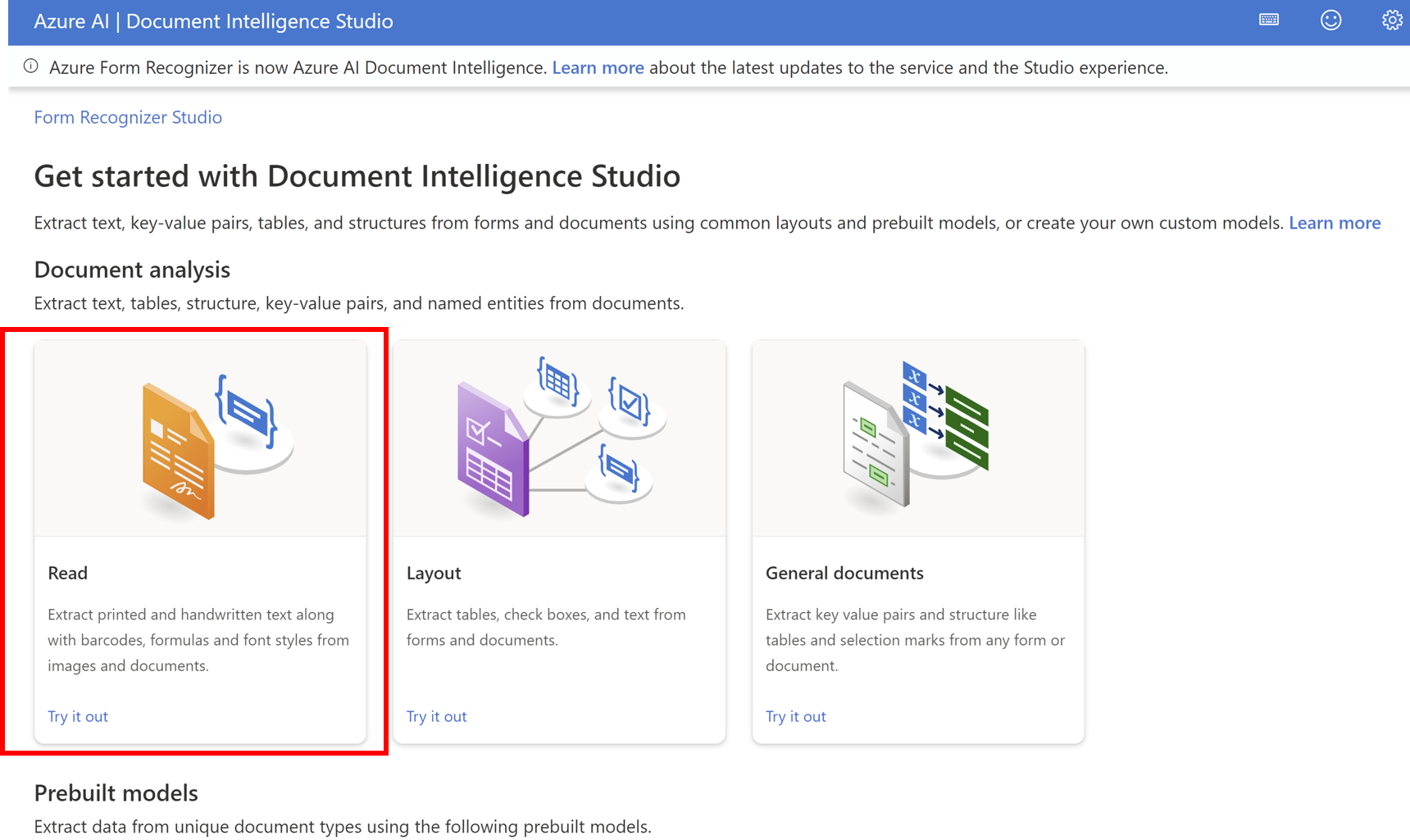
- 解析対象のファイルを選択、Run analysisをクリックすると結果が表示されます
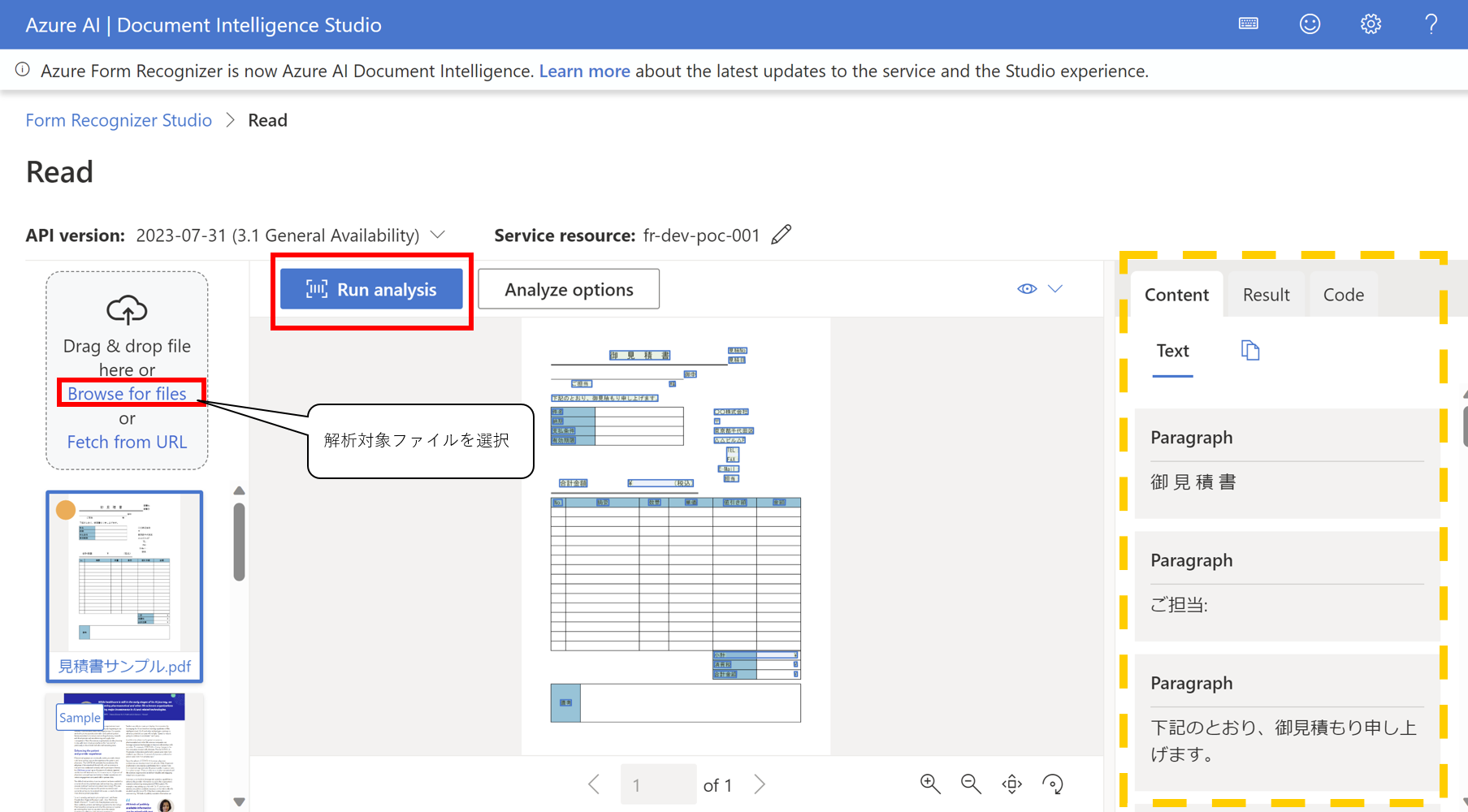
また、Codeタブをクリックすると、解析するときに使用するPythonコードを確認することができる。

Layoutを使用する
Layoutはテキスト + ドキュメント構造を抽出する機能です。
ドキュメントの構造とは、ドキュメント上のテキストがテーブル形式のドキュメントを持っているかということ示します。
- Layoutをクリックする
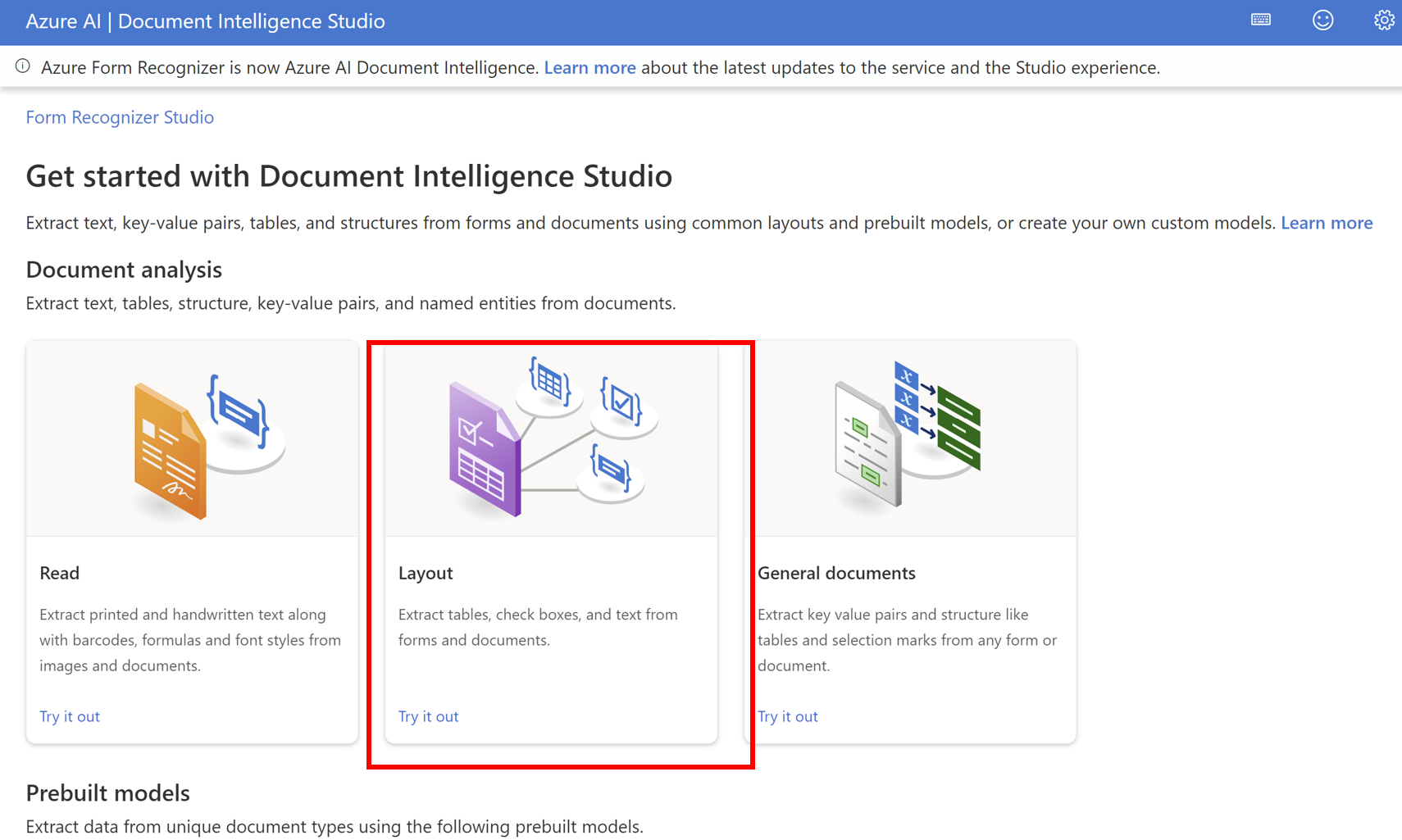
- 解析対象のファイルを選択、Run analysisをクリックすると結果が表示されます
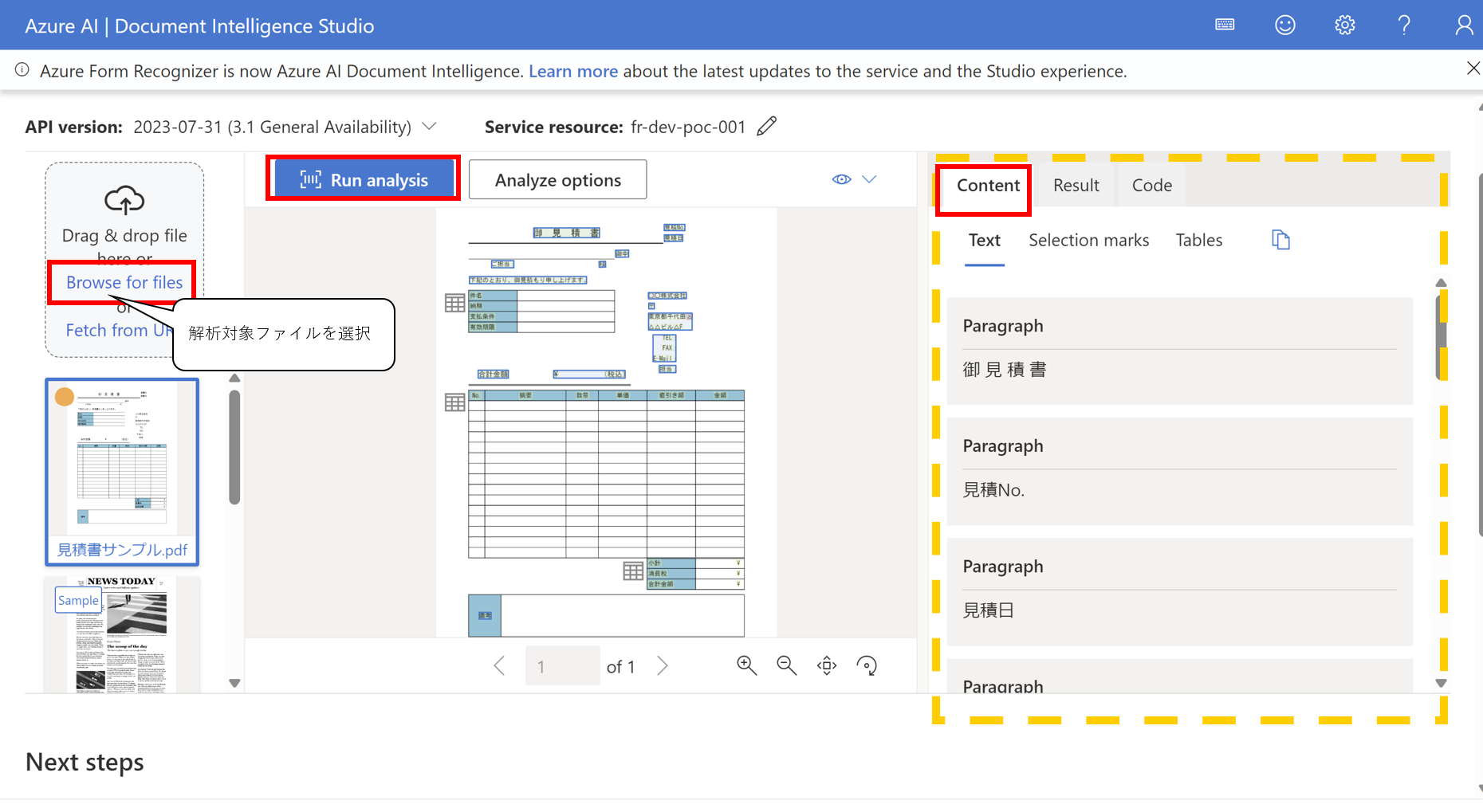
- Selection marksタブをクリックすると選択肢形式として認識されたテキストの比率を表示できる
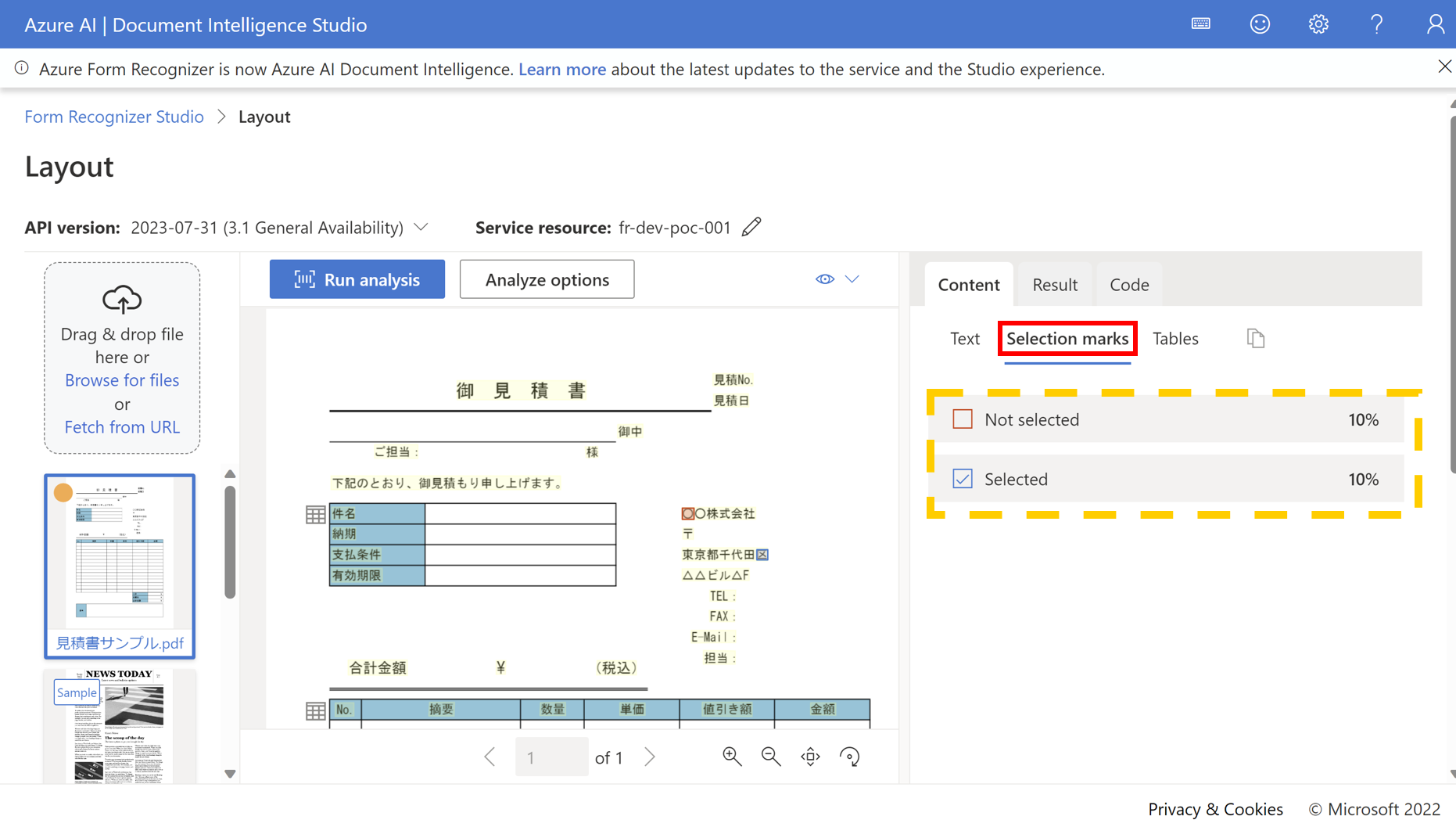
- Tablesタブをクリックするとテーブル形式として認識されたテキストを表示できる
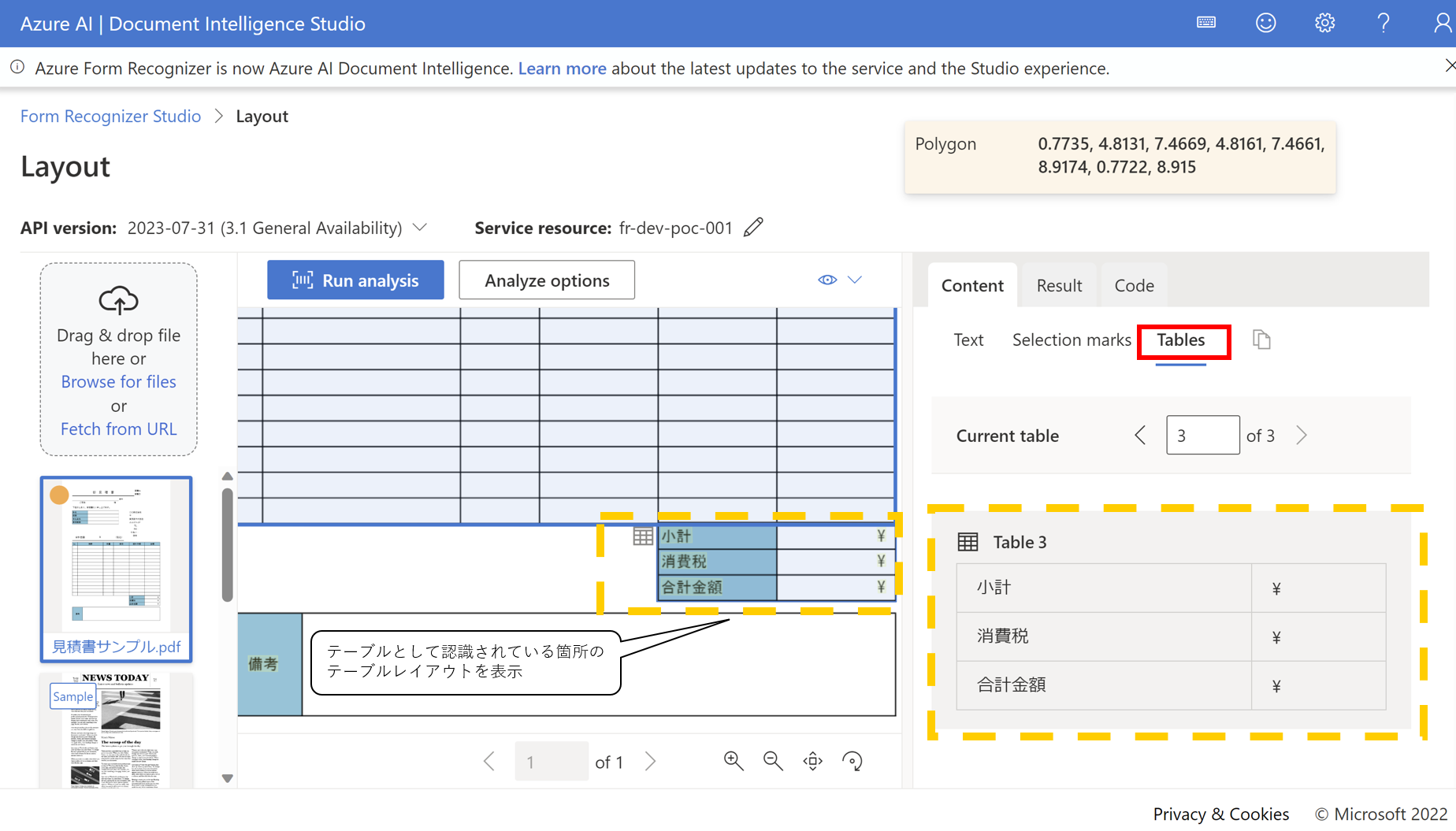
General Documentを使用する
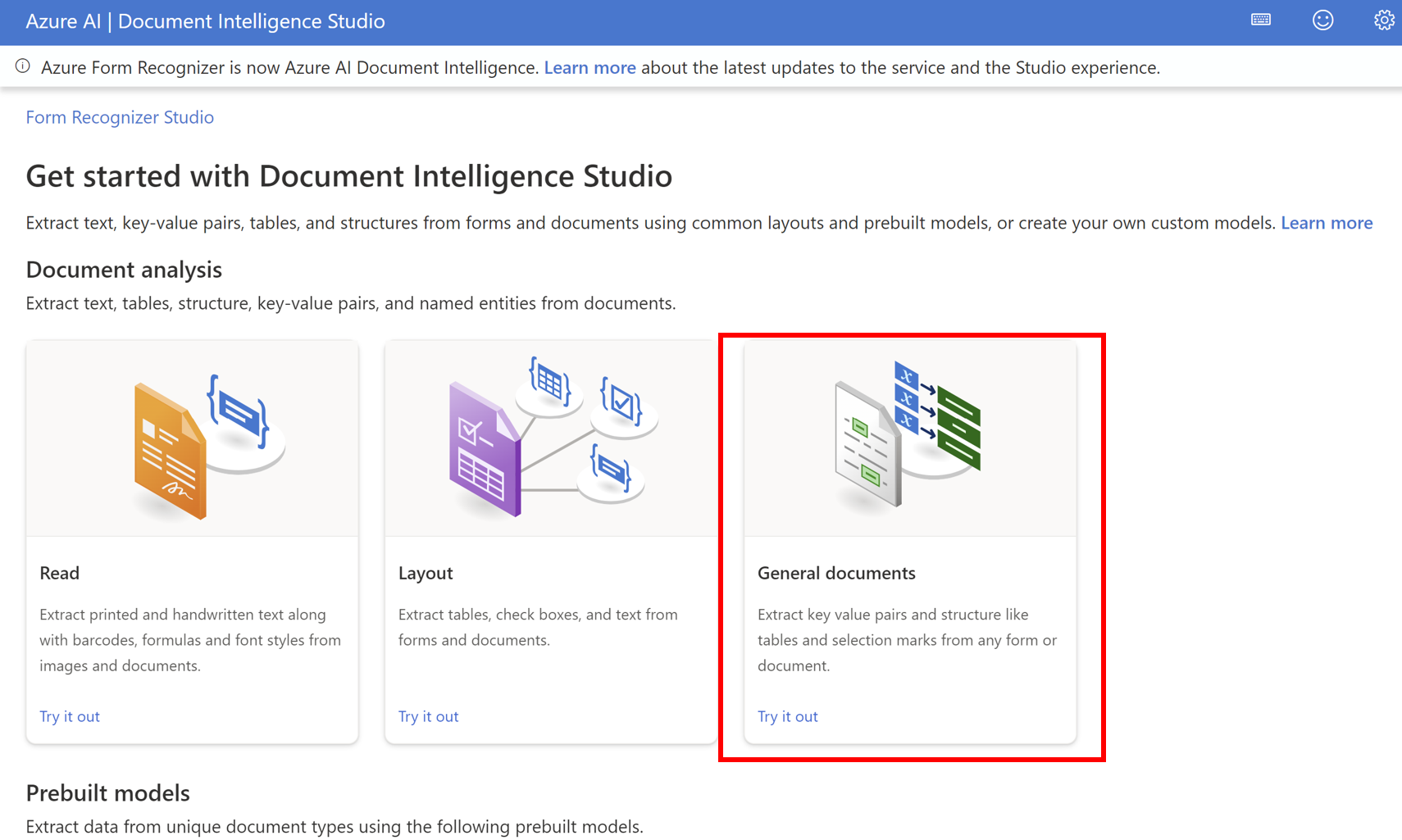
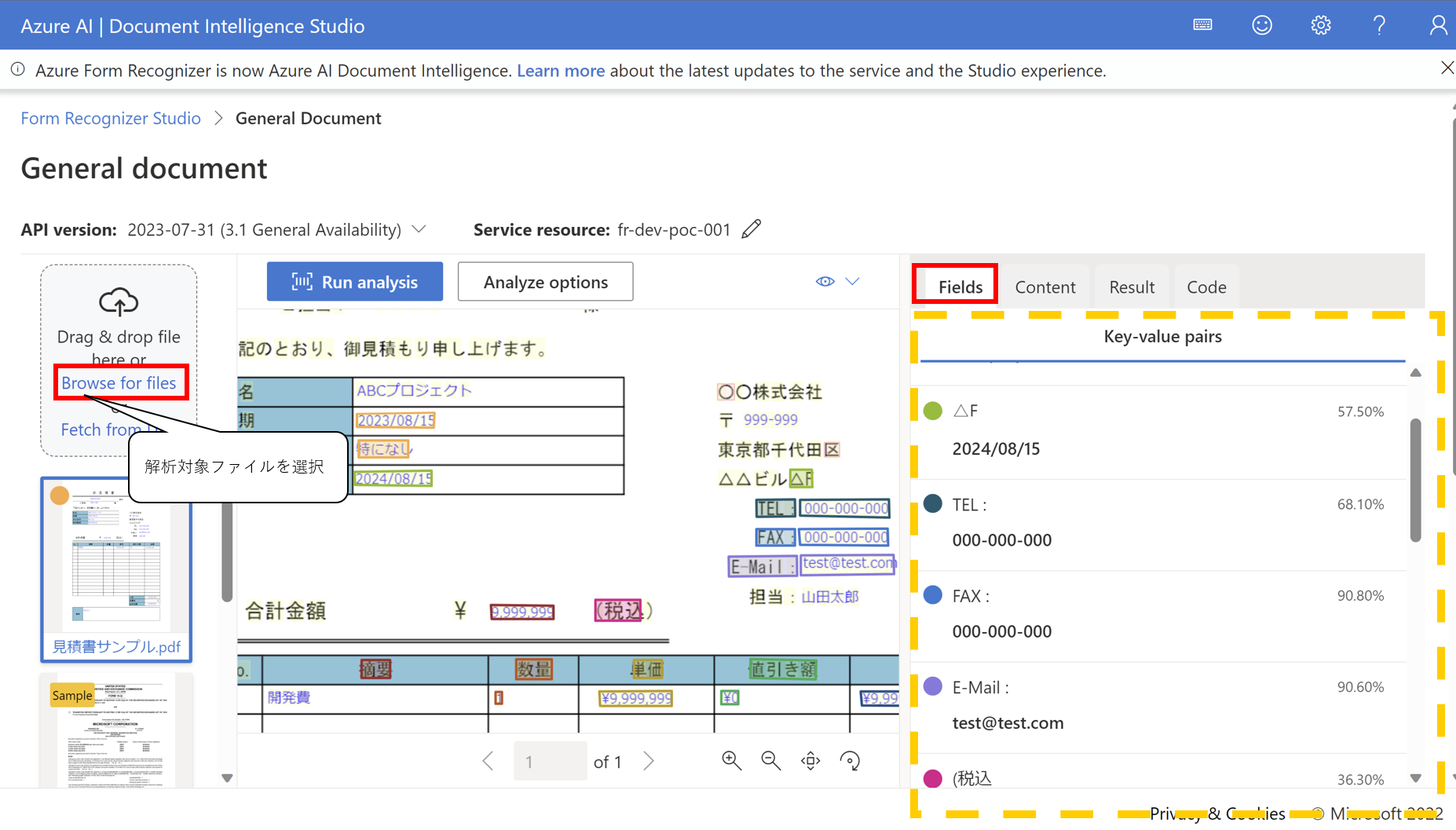
General Documentはテキスト + ドキュメント構造 + キーバリューのペアを抽出する機能です。
キーバリューのペアとは、ドキュメント上で電話番号というテキストと、実際の電話番号の値(000-000-000など)のようにキーと値の関係性をもつテキストを抽出する機能です。
- General Documentをクリック
- 解析対象のファイルを選択し、Run analysisをクリックすると結果が表示されます
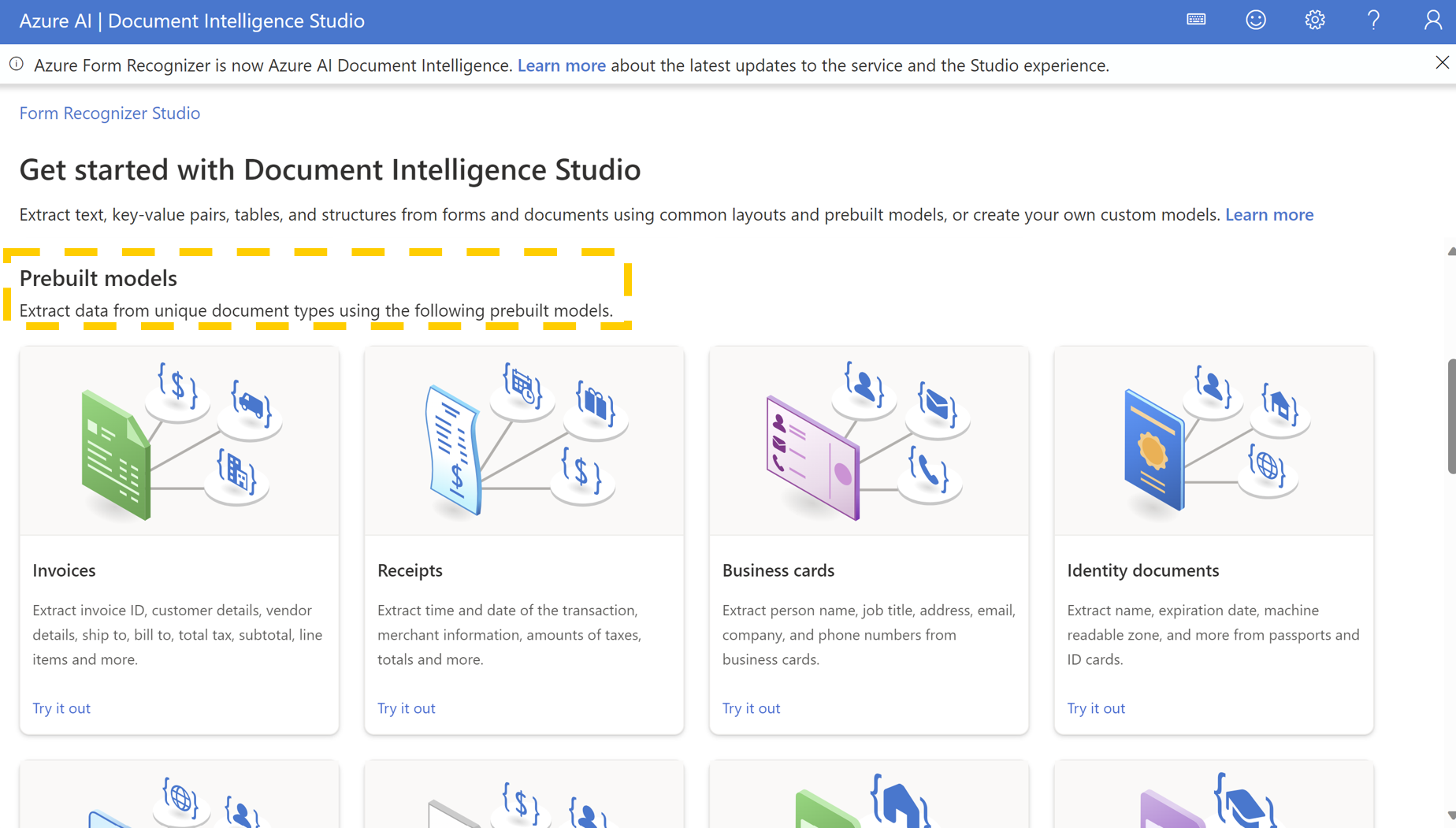
Prebuilt modles(組み込みモデル)を使用する
Prebuilt models APIでは、以下の事前学習済みのドキュメントを解析することが可能です。
- 請求書
- 領収書
- ID
- 健康保険証
- 名刺
- 契約
- 米国税 W-2 フォーム
- 米国税 1098 フォーム
- 米国税 1098-E フォーム
- 米国税 1098-T フォーム
Custom models(カスタムモデル)を使用する
Custom modelsでは、以下の2つのAPIを使用することができます。
- Custom Extract Model
- Custom Classification Model
Custom Extract Model
Custom Extract Modelは、ドキュメント内の固定された位置にあるテキスト(ドキュメントのタイトルなど)をラベルとしてモデルに学習さえ、そのテキストを抽出することができる機能です。
- Custom extract modelをクリック
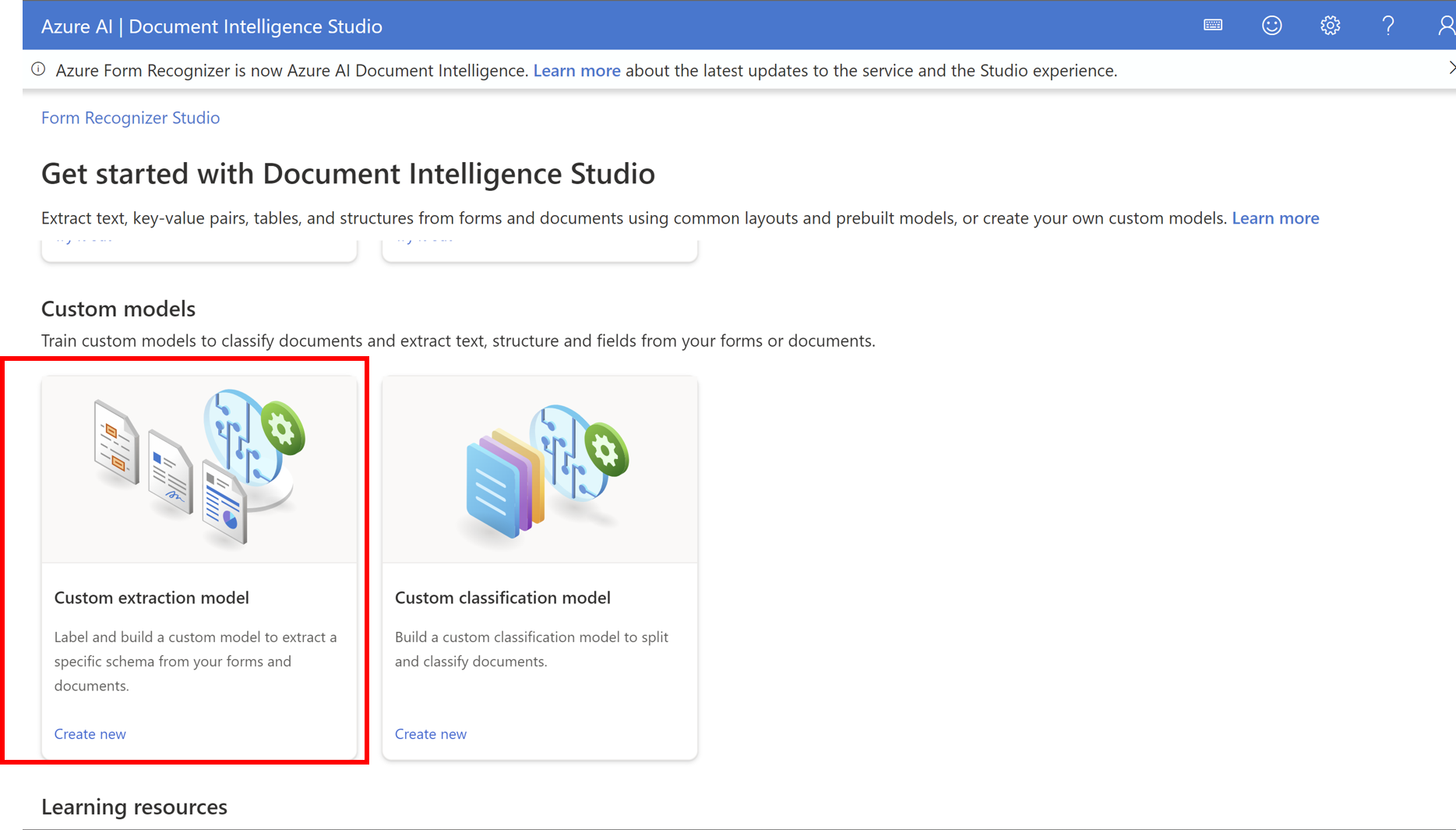
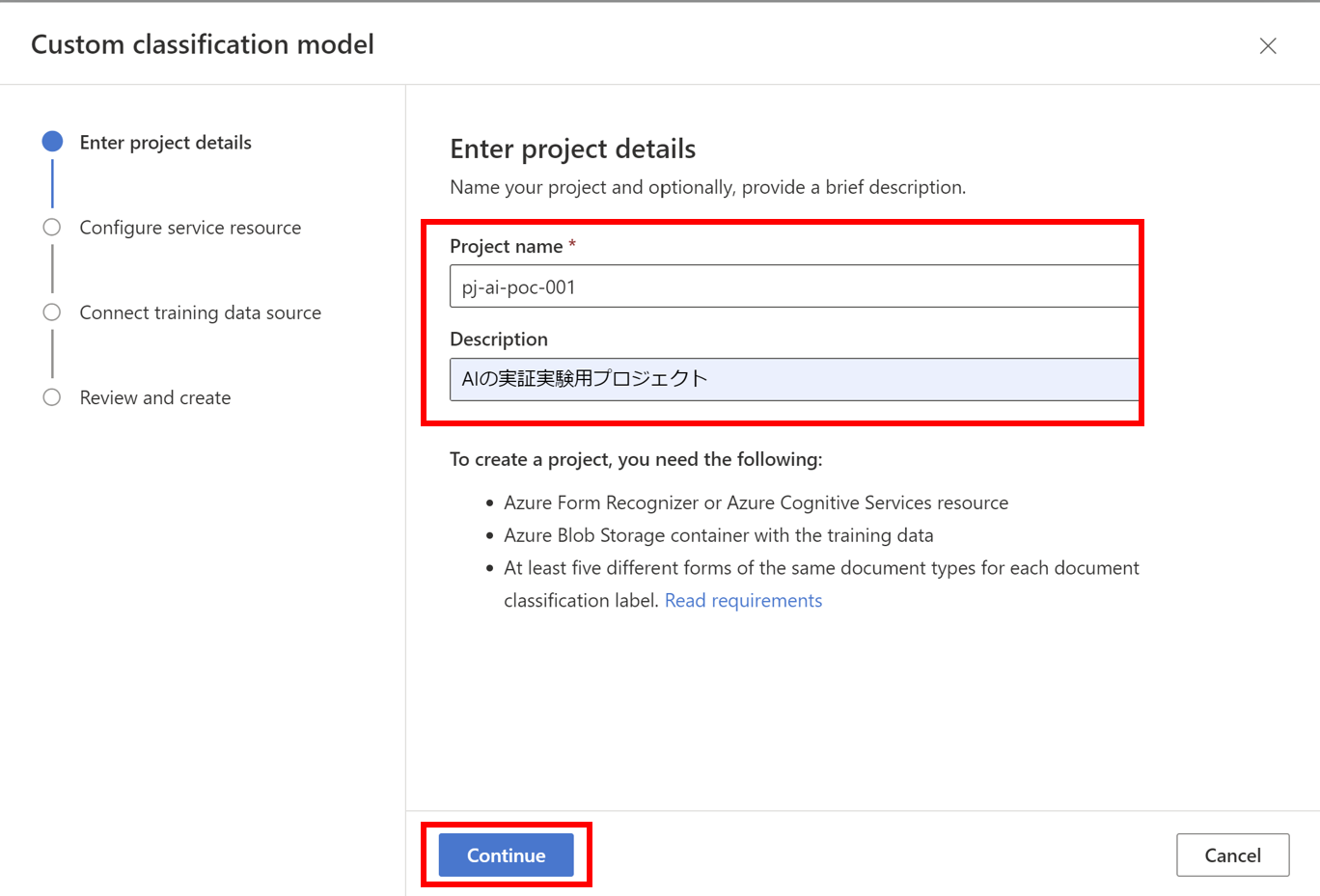
- 初回はカスタムモデルを作成するためのプロジェクトが必要なので、プロジェクトを作成します
プロジェクトを作成すると
プロジェクト名.fottというファイルが接続先のストレージアカウントのコンテナ直下に作成されます。
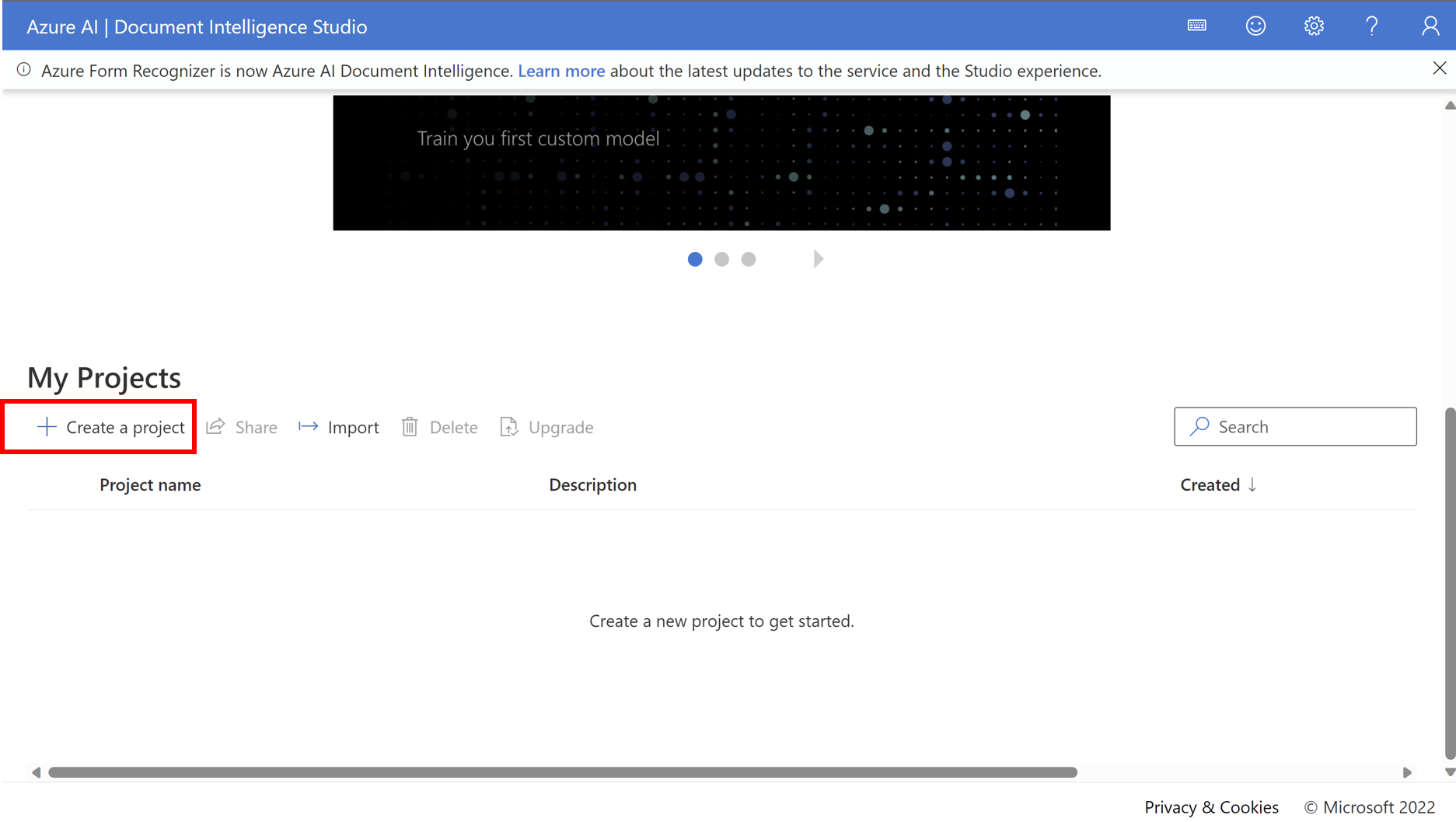
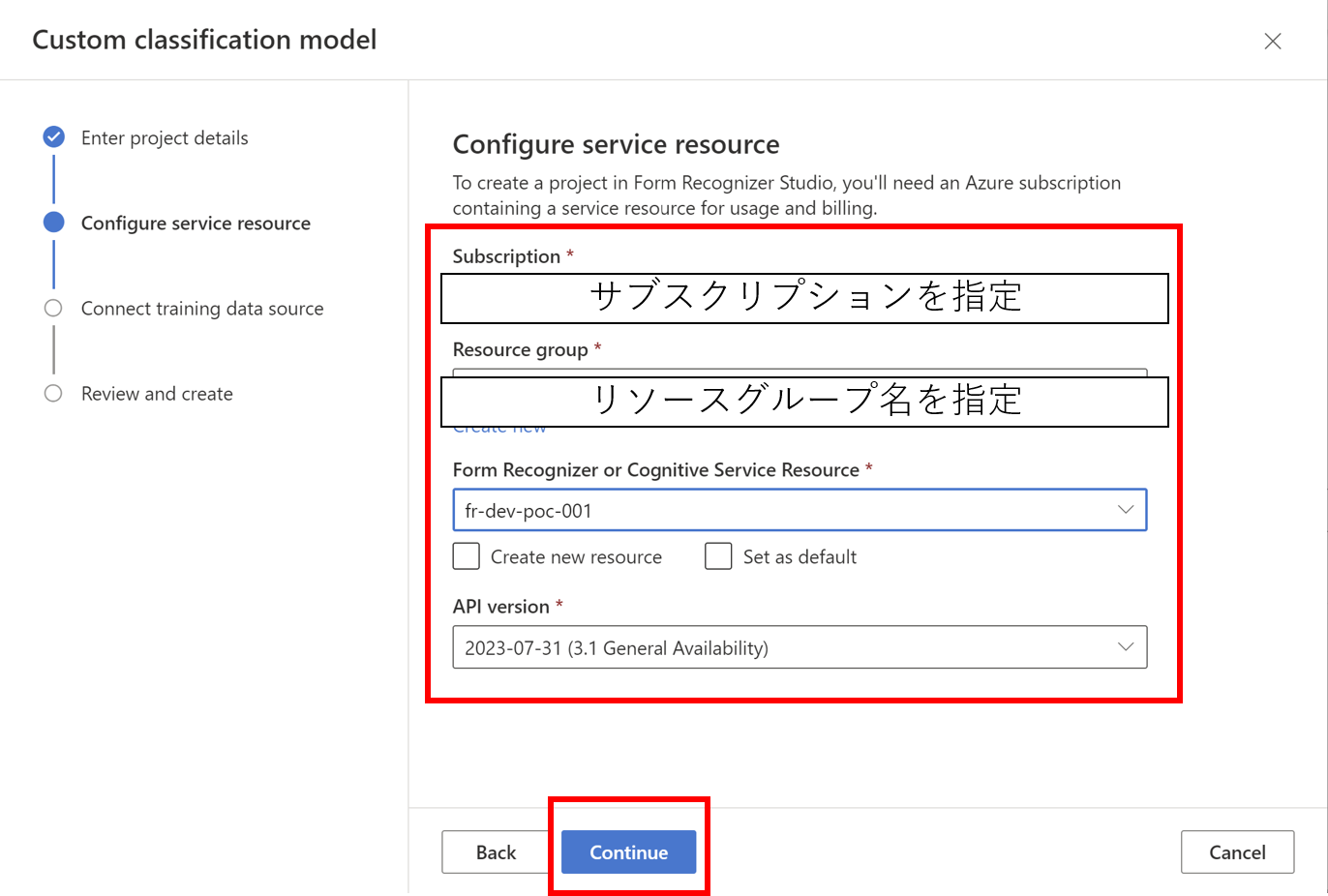
- 必要情報を入力し、作成していきます
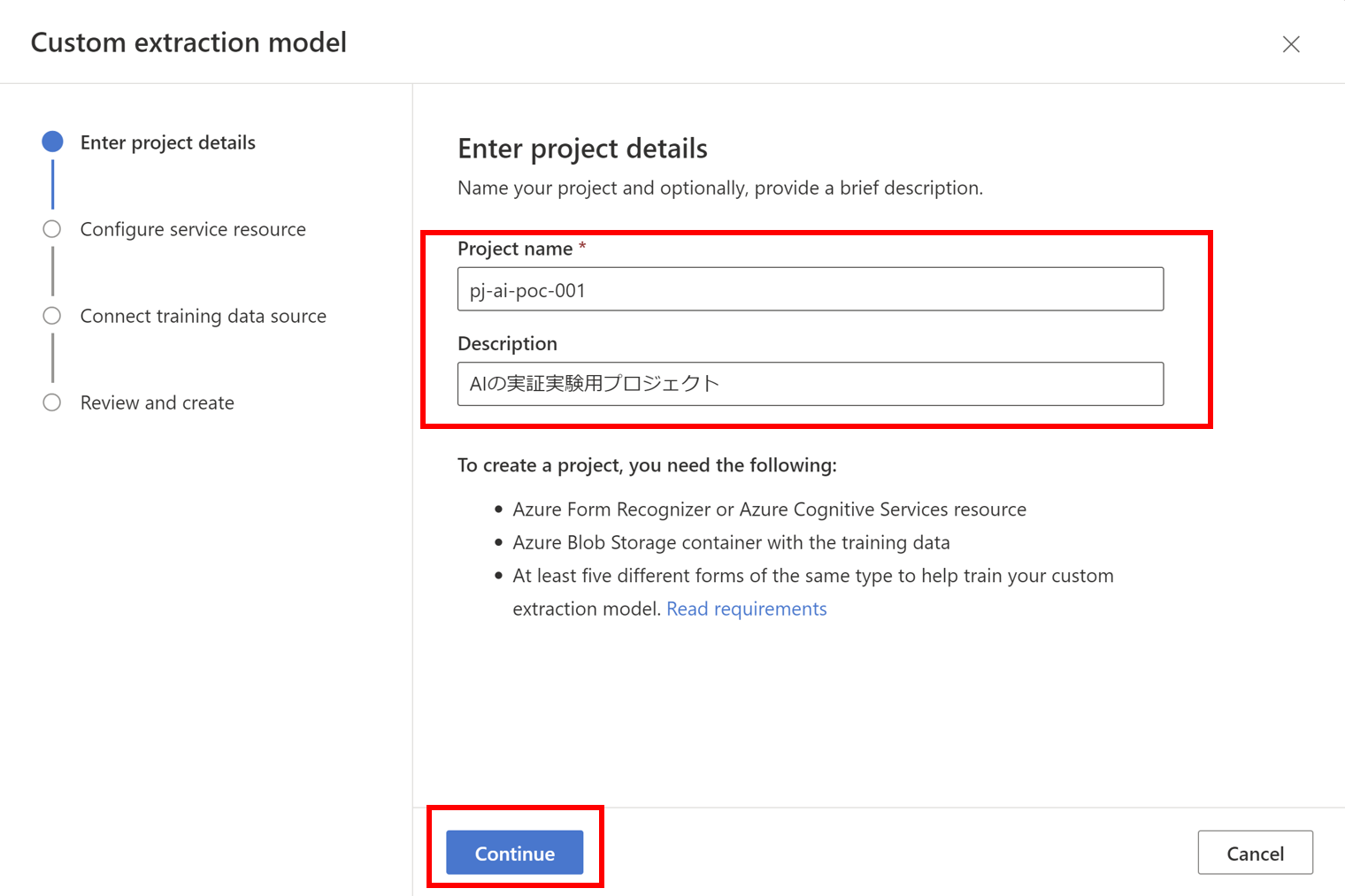
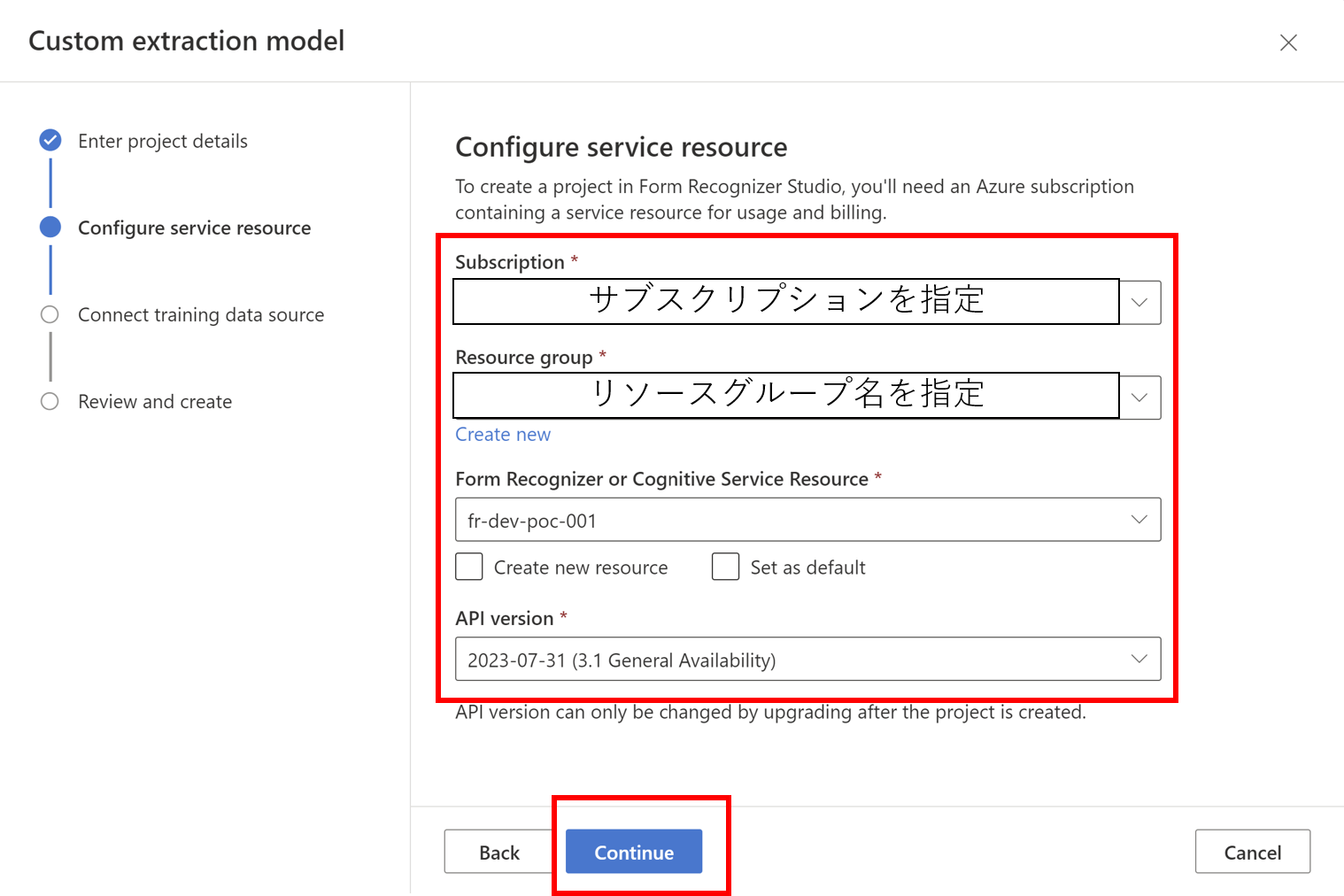
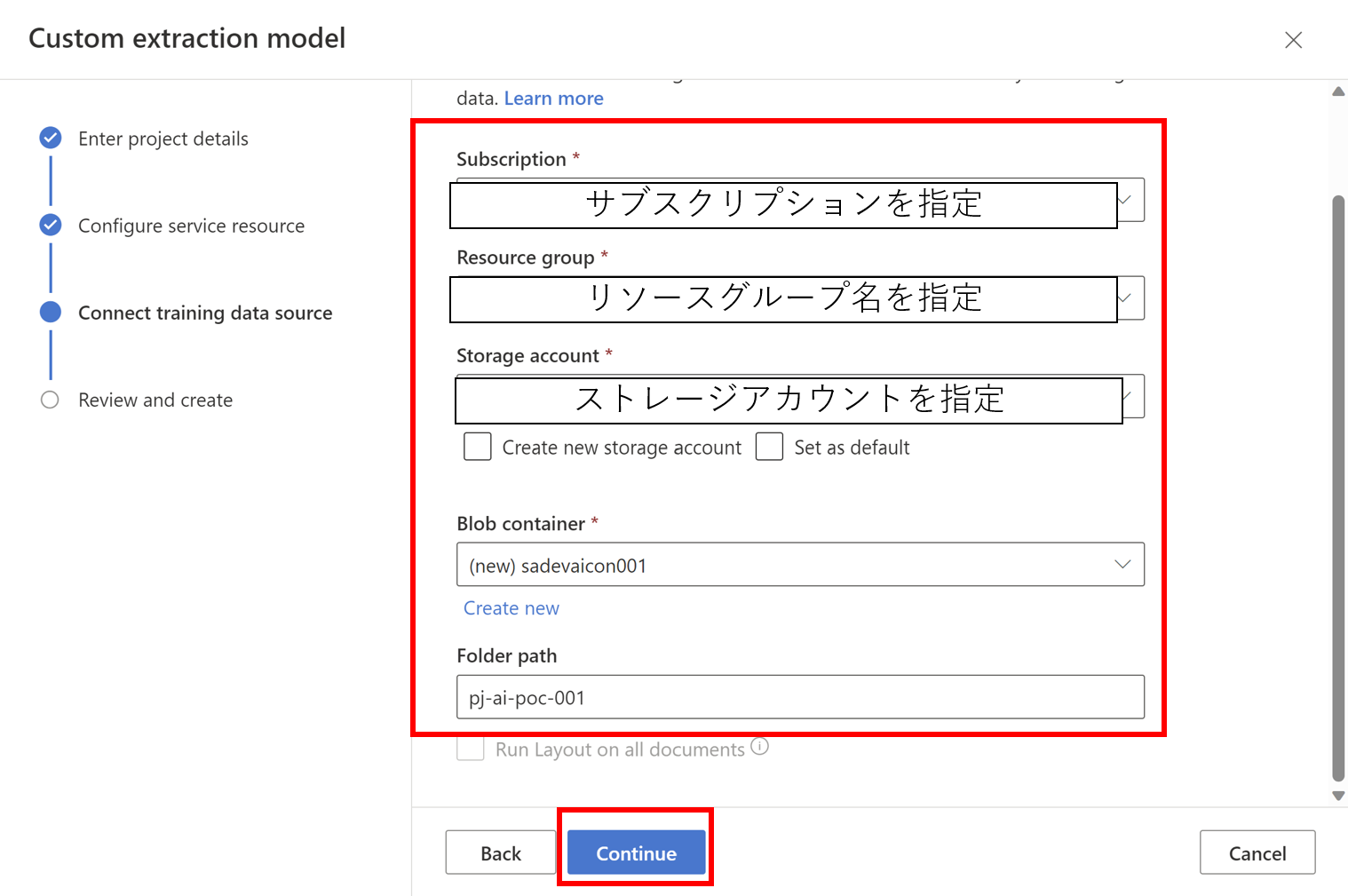
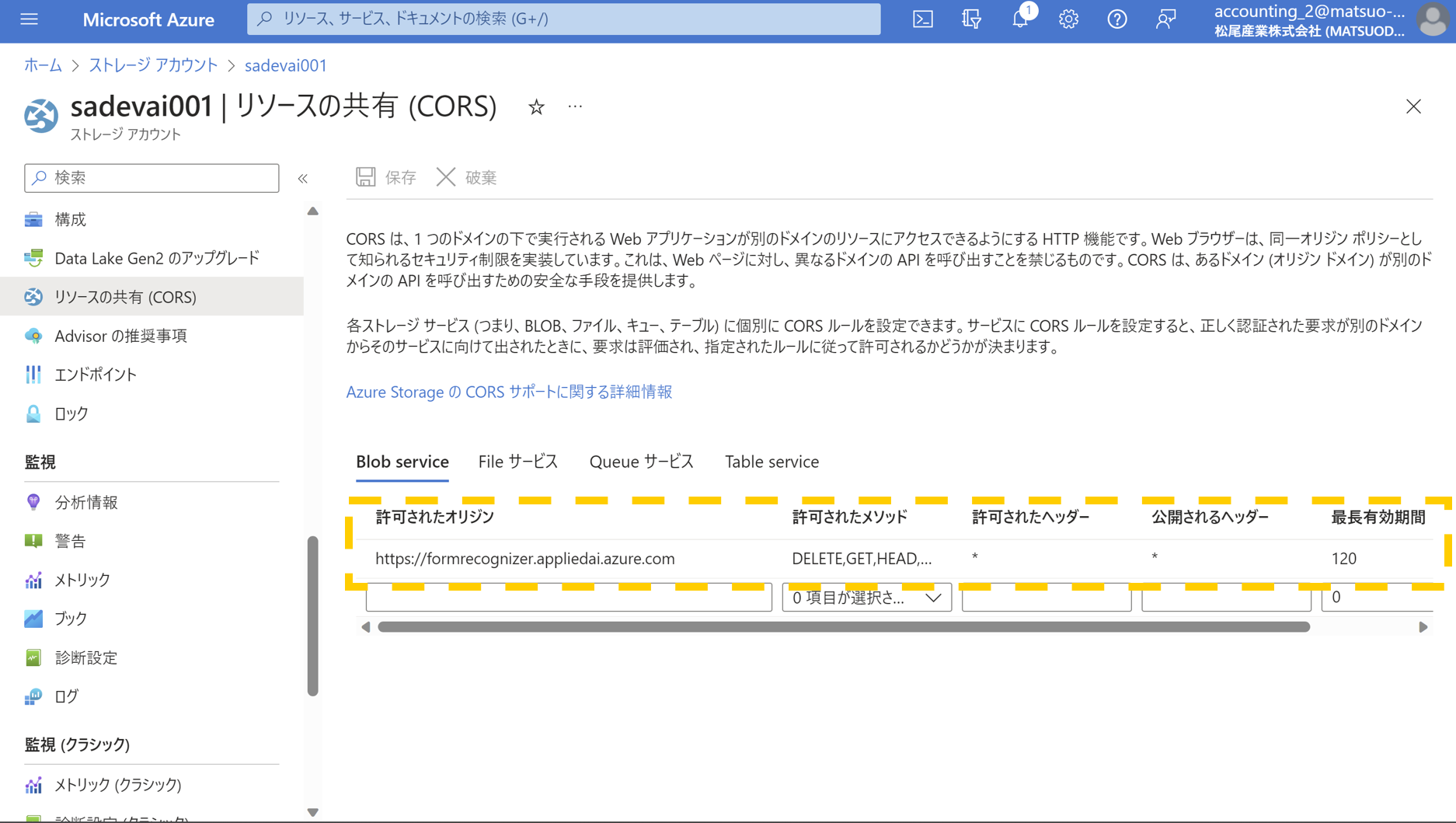
- 作成完了すると指定したストレージアカウントにCORSの設定が行われます
- Azure Document Studioに戻り、Label dataから対象ファイルを選択し、ラベルとして学習させるテキストフィールドを追加します 以下の例ではドキュメントのタイトルを認識させるための、書類分類というテキストフィールドを作成します
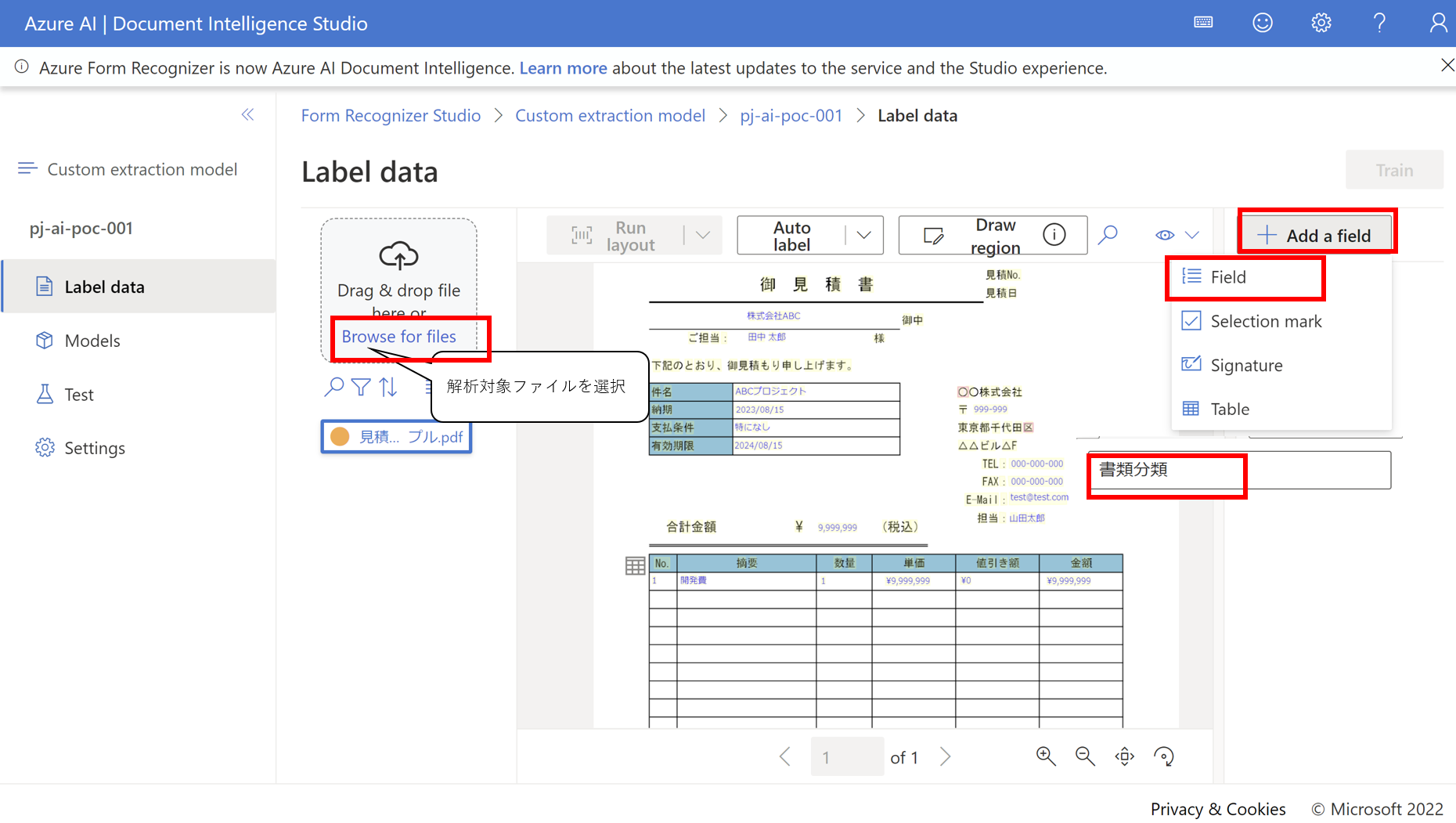
- フィールドとして抽出するテキストをドラッグして選択します
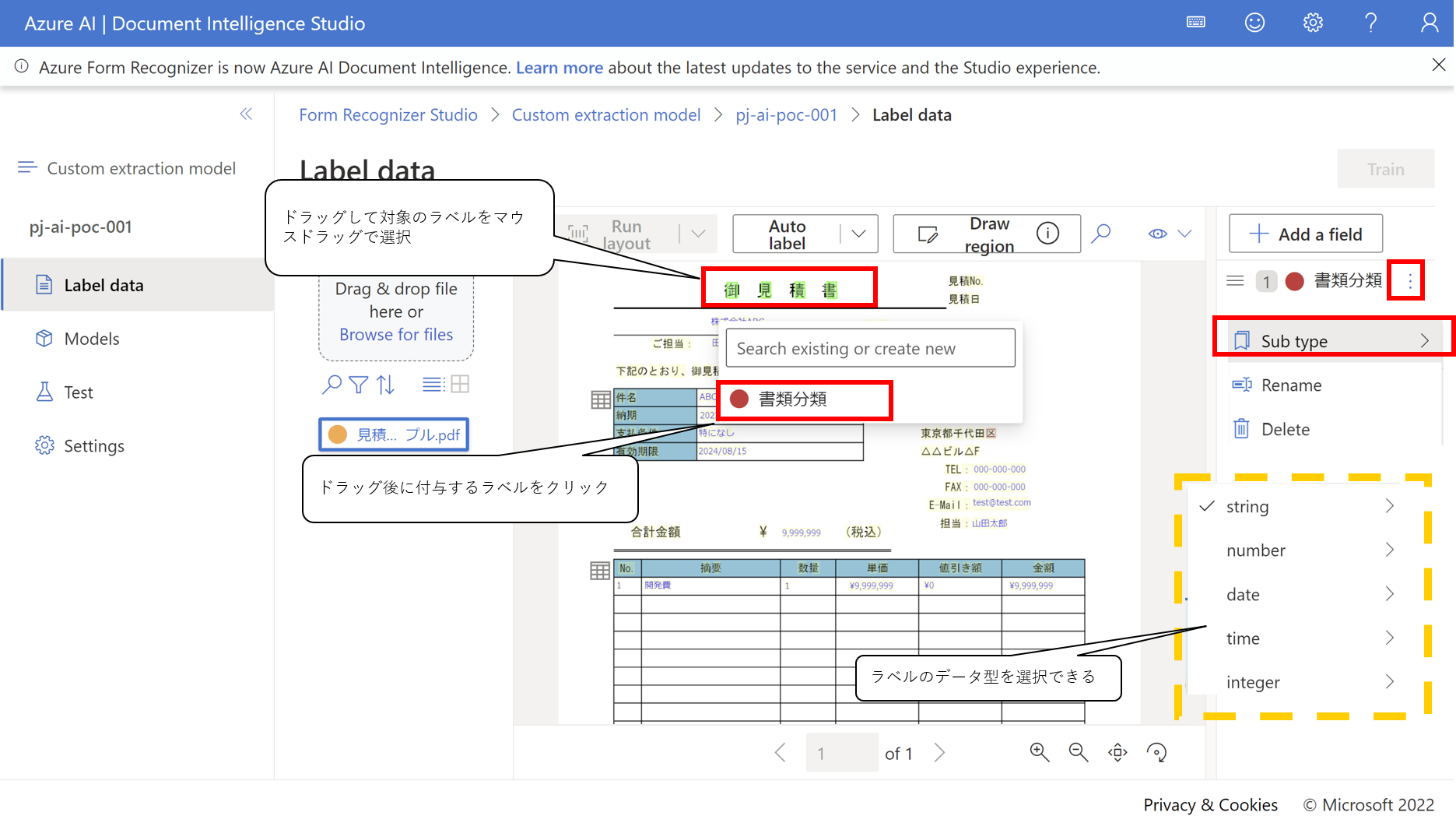
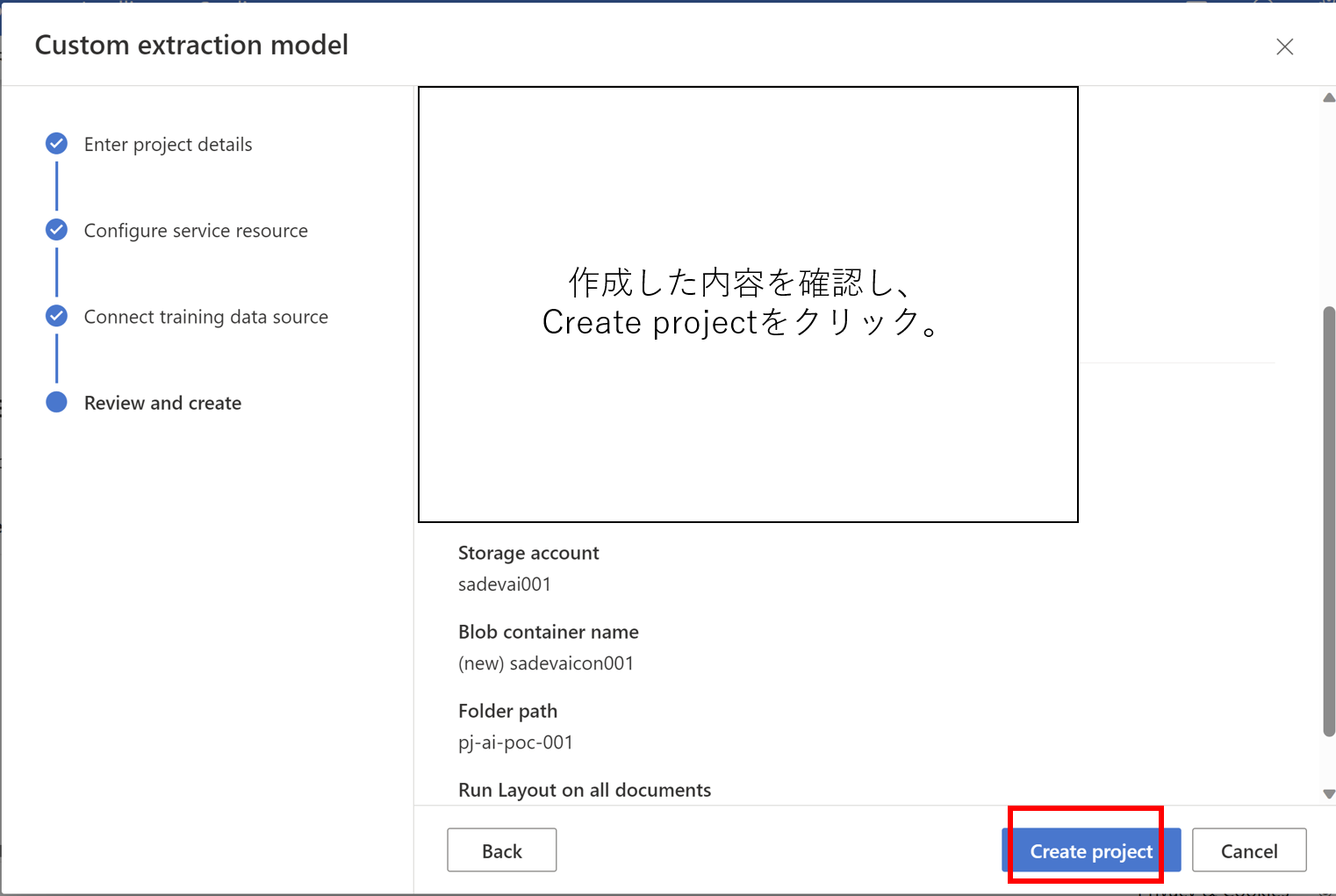
- Trainをクリックして、モデル作成画面を表示します
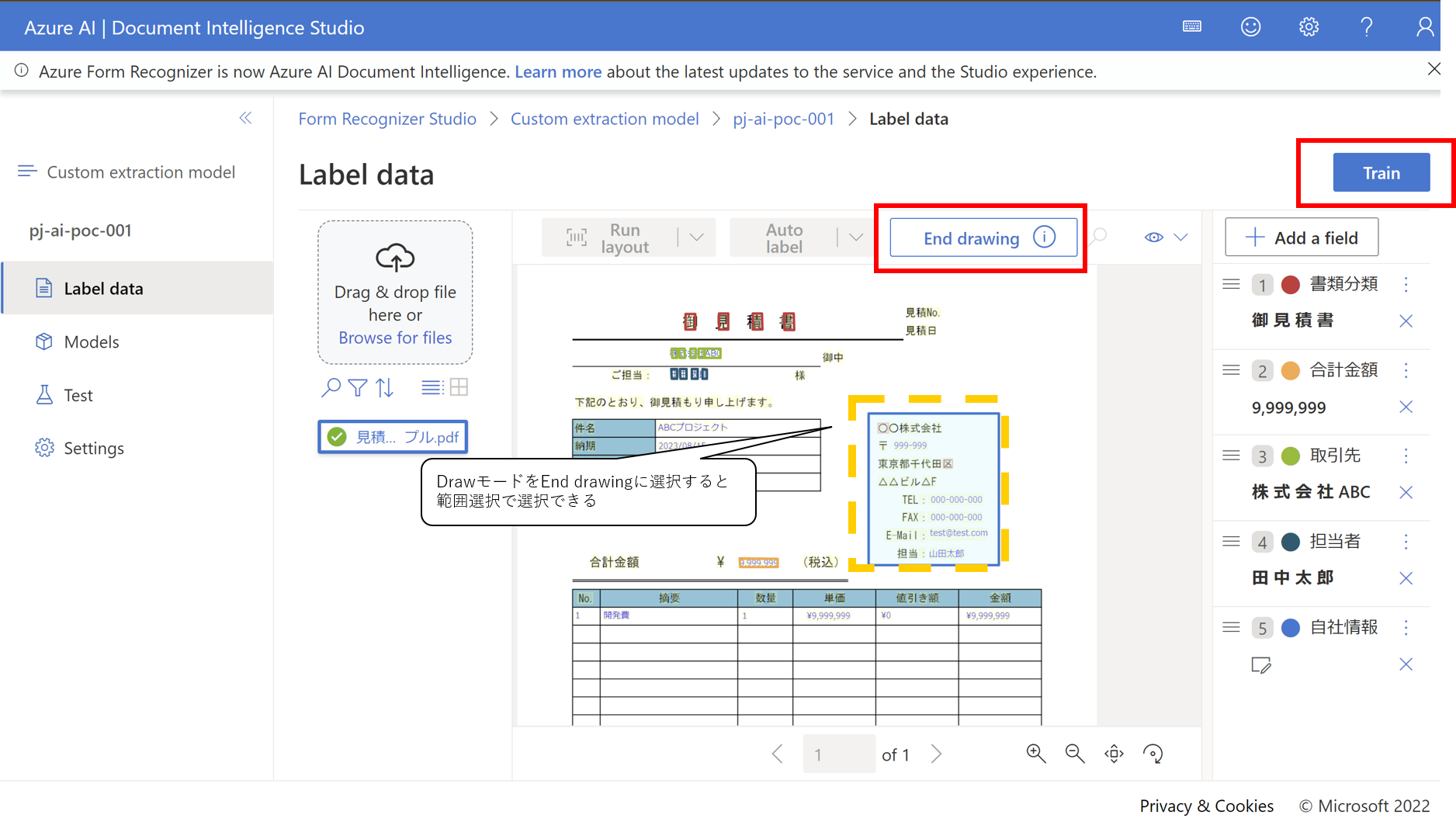
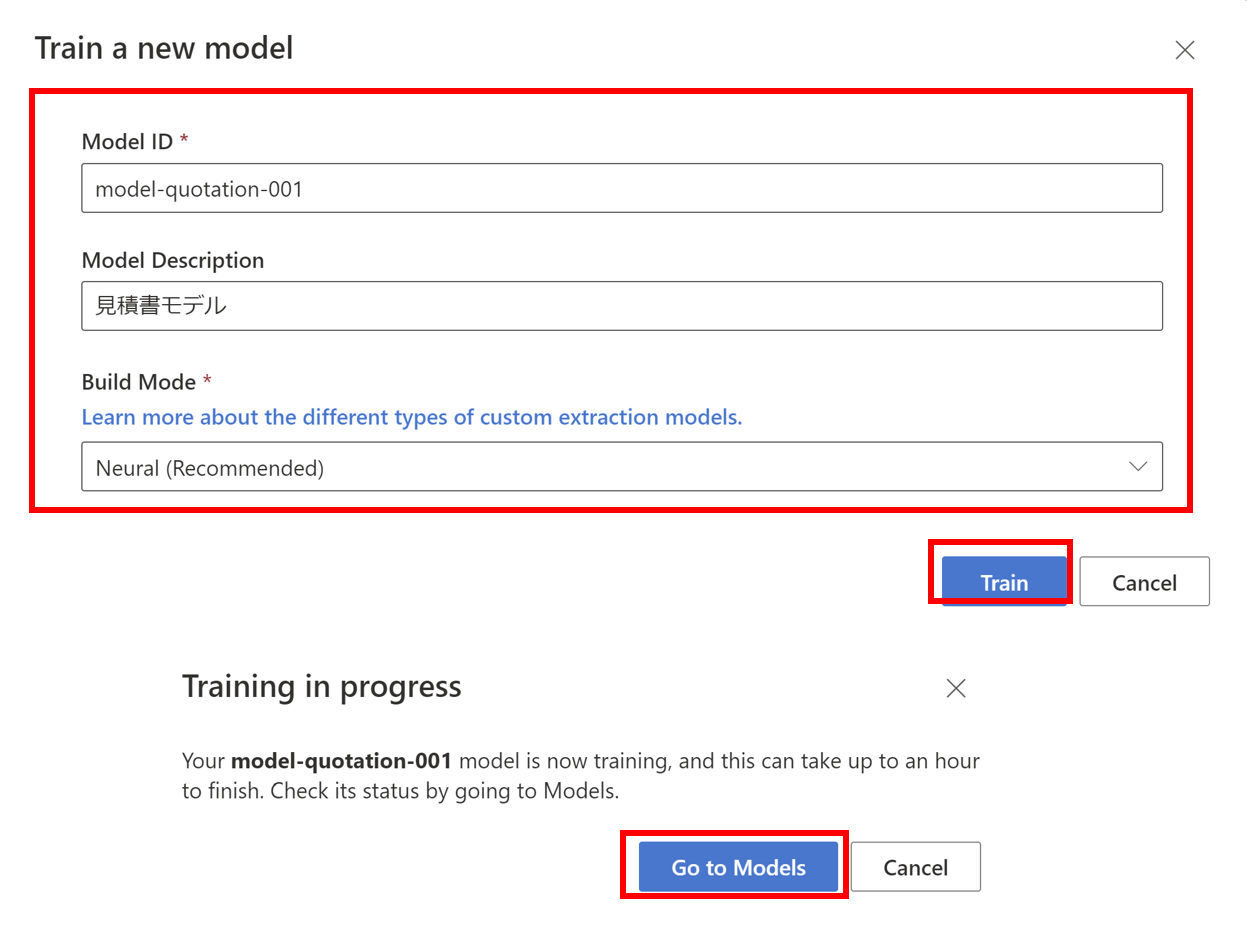
- Trainをクリックすると学習が開始され、Get to Modelsをクリックするとモデルの作成状況がわかります
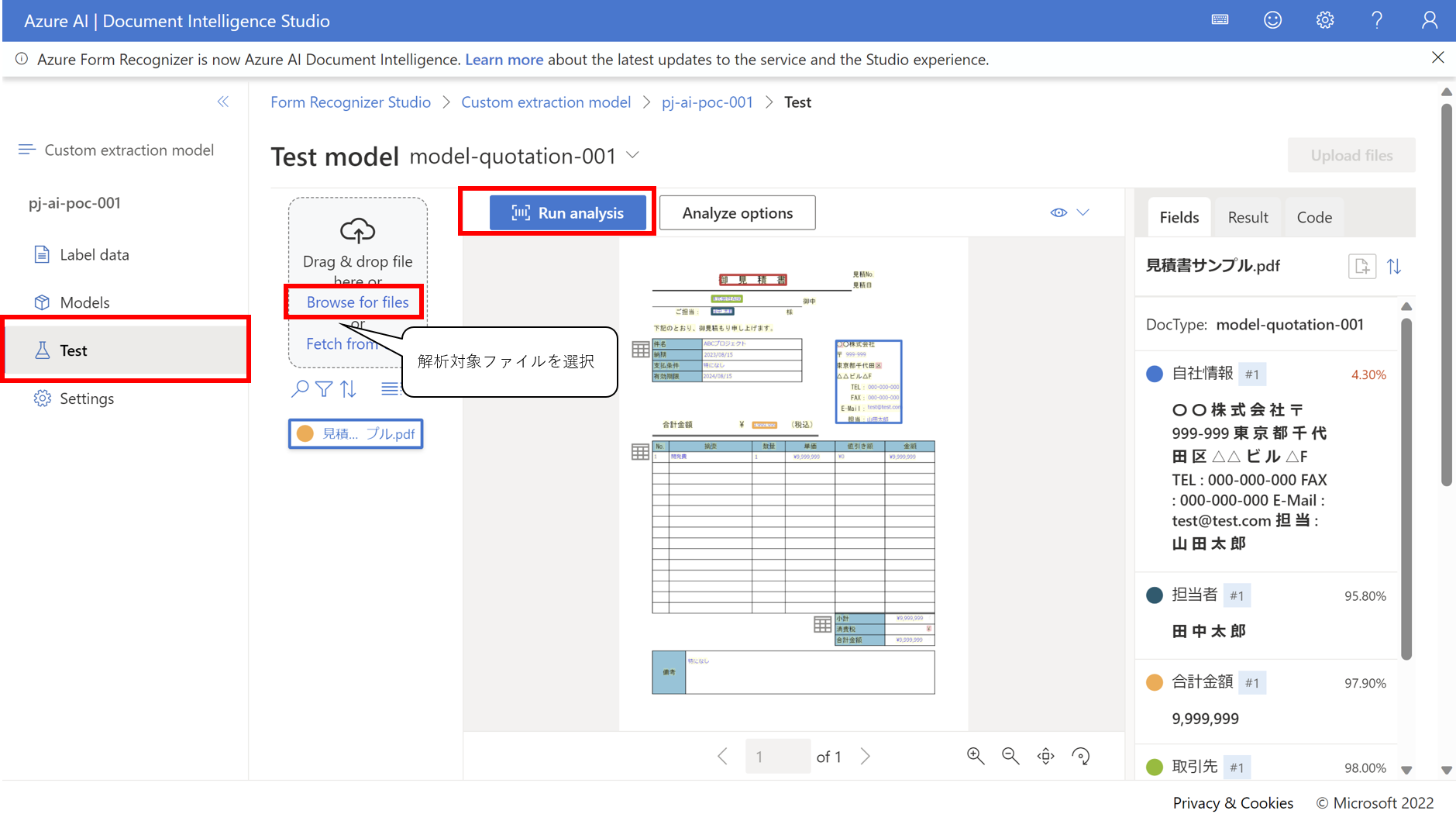
- TestタブでRun analysisをクリックすると作成したモデルでテストをすることができます
以下にあるようにフィールドとして設定したテキストがドキュメントから抽出できていることがわかります
- 補足テーブル形式のフィールド
Azure Document Intelligenceではテーブル形式のフィールドも設定することも可能です。
デフォルトでもテーブル認識機能はついていますが、結合セルがあったり表の形式が不規則だと、テーブルとして認識されないことがあります。
このようなケースでは、テーブルフィールドを作成し、ファイル中のテーブルと関連付けを行う必要があります。
Custom Classification Model
Custom Classification Modelではドキュメントが何のドキュメントなのかを解析することができます。
- Custom classification modelをクリック
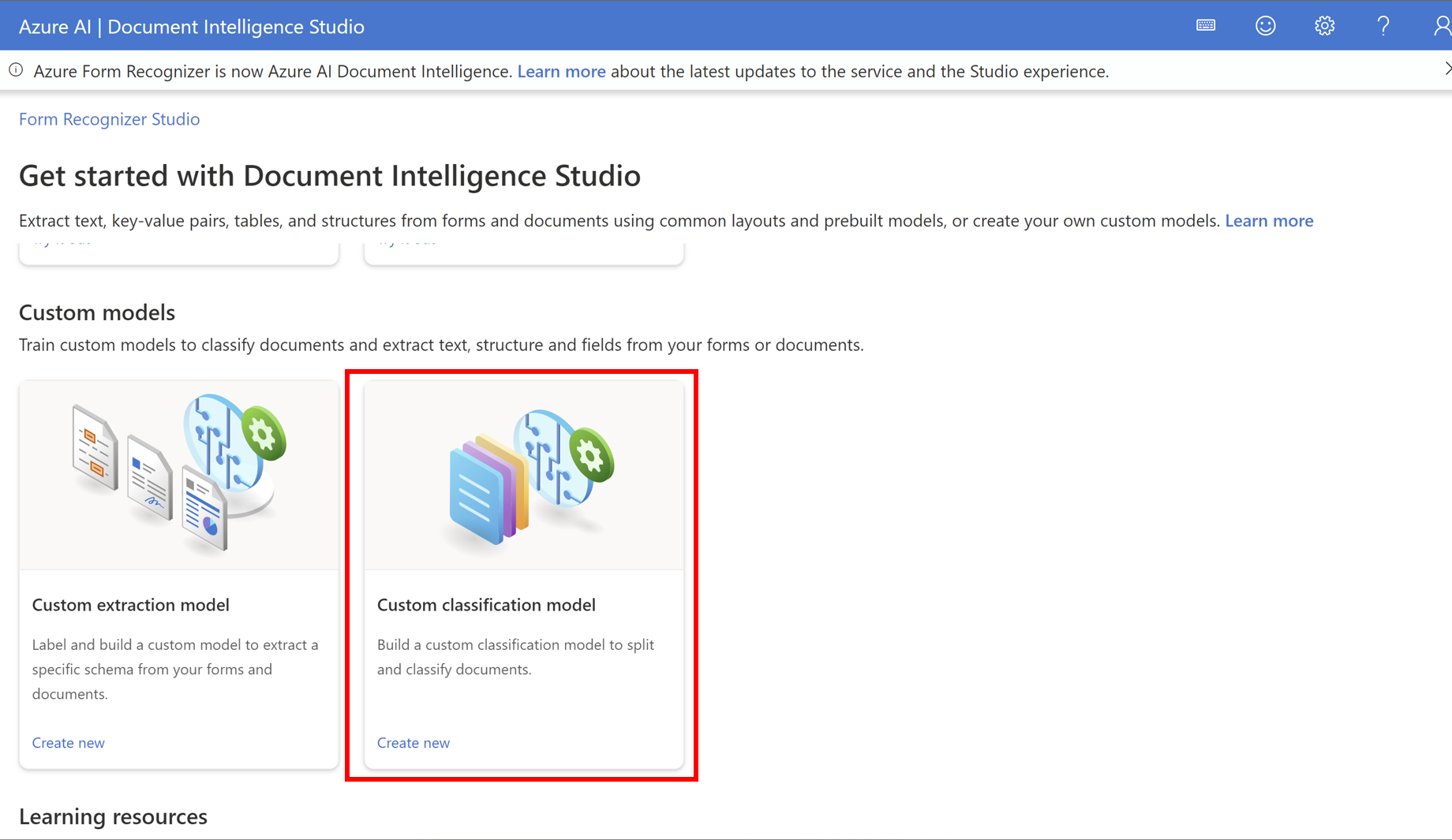
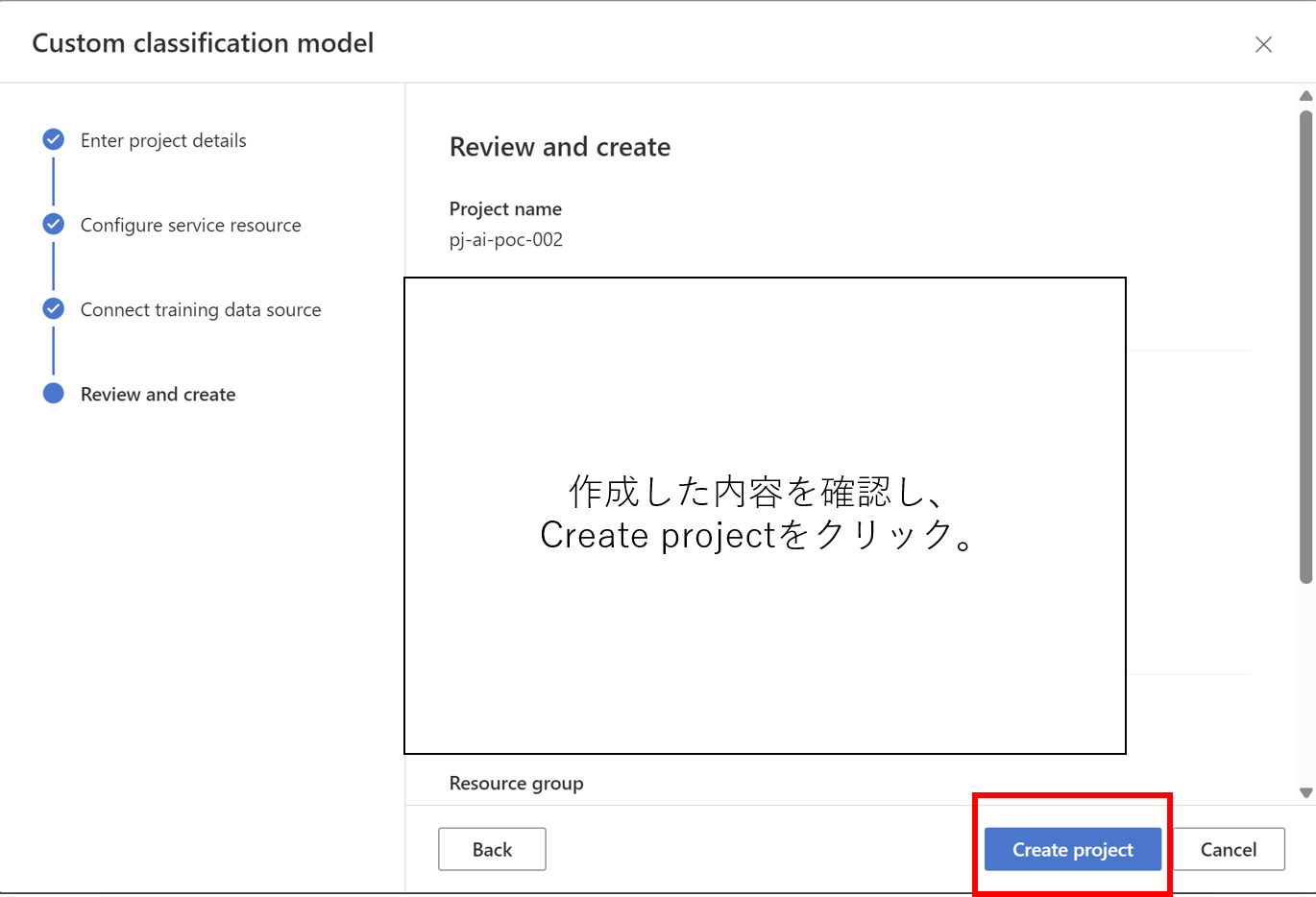
- プロジェクトを作成します
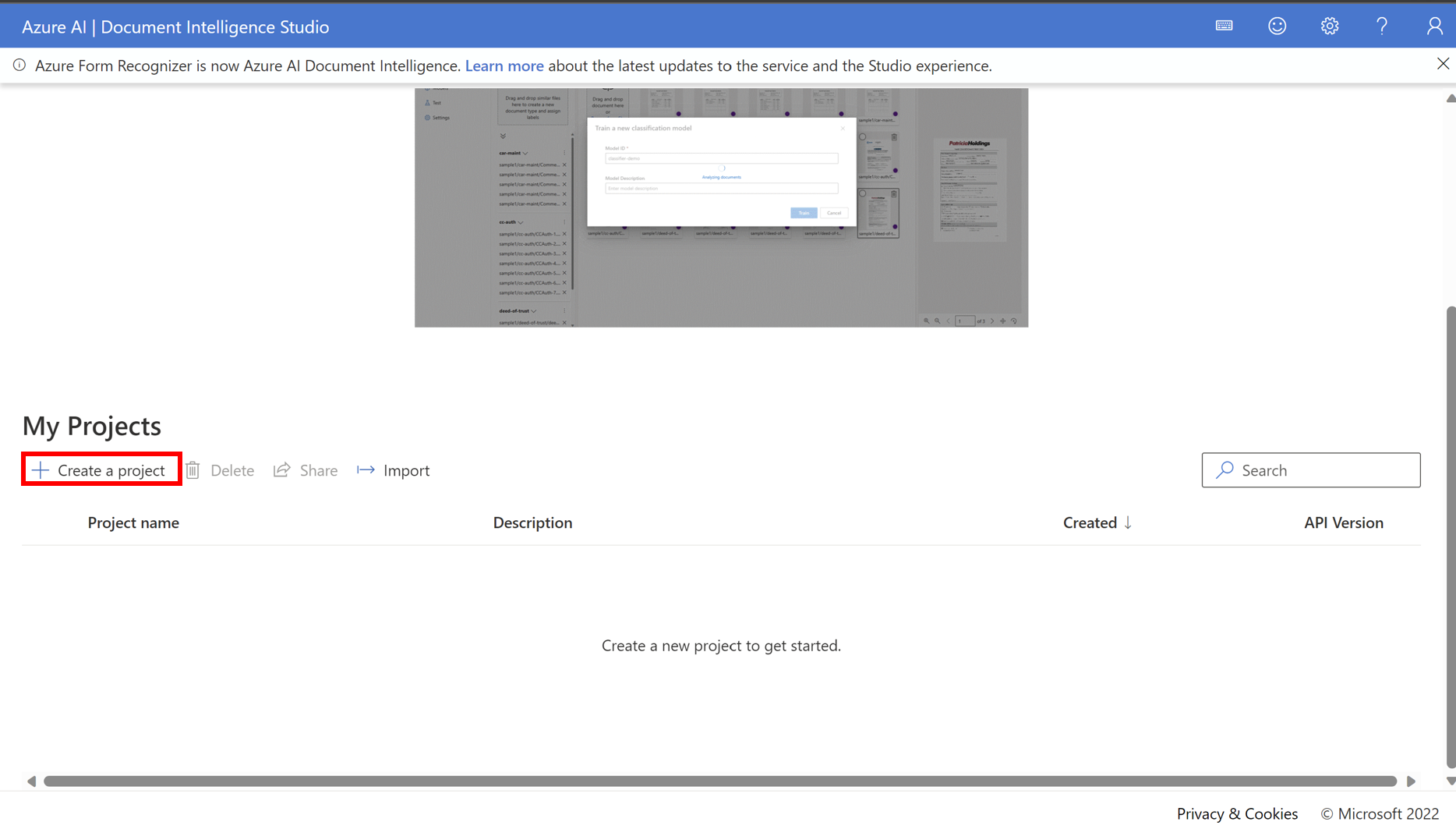
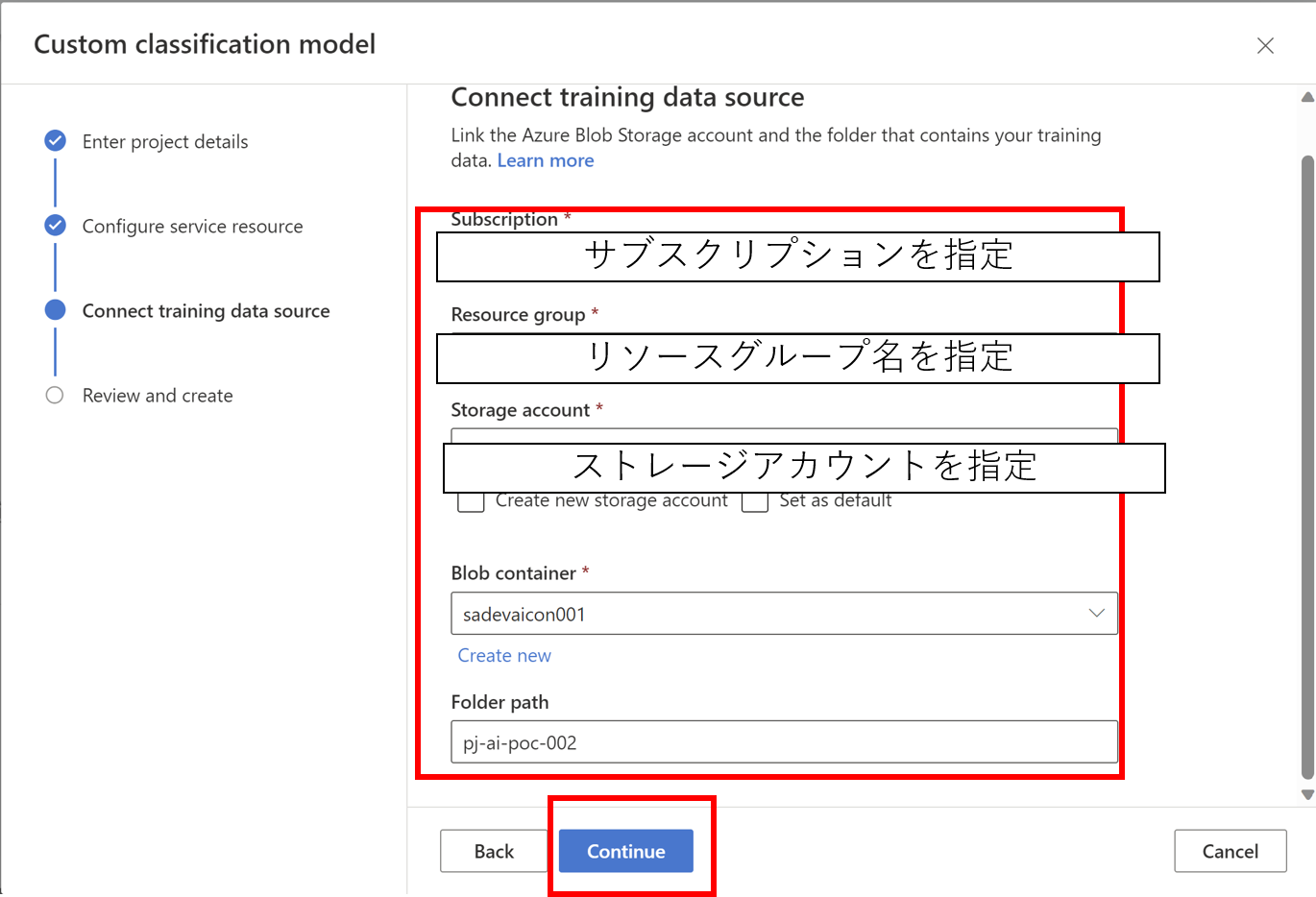
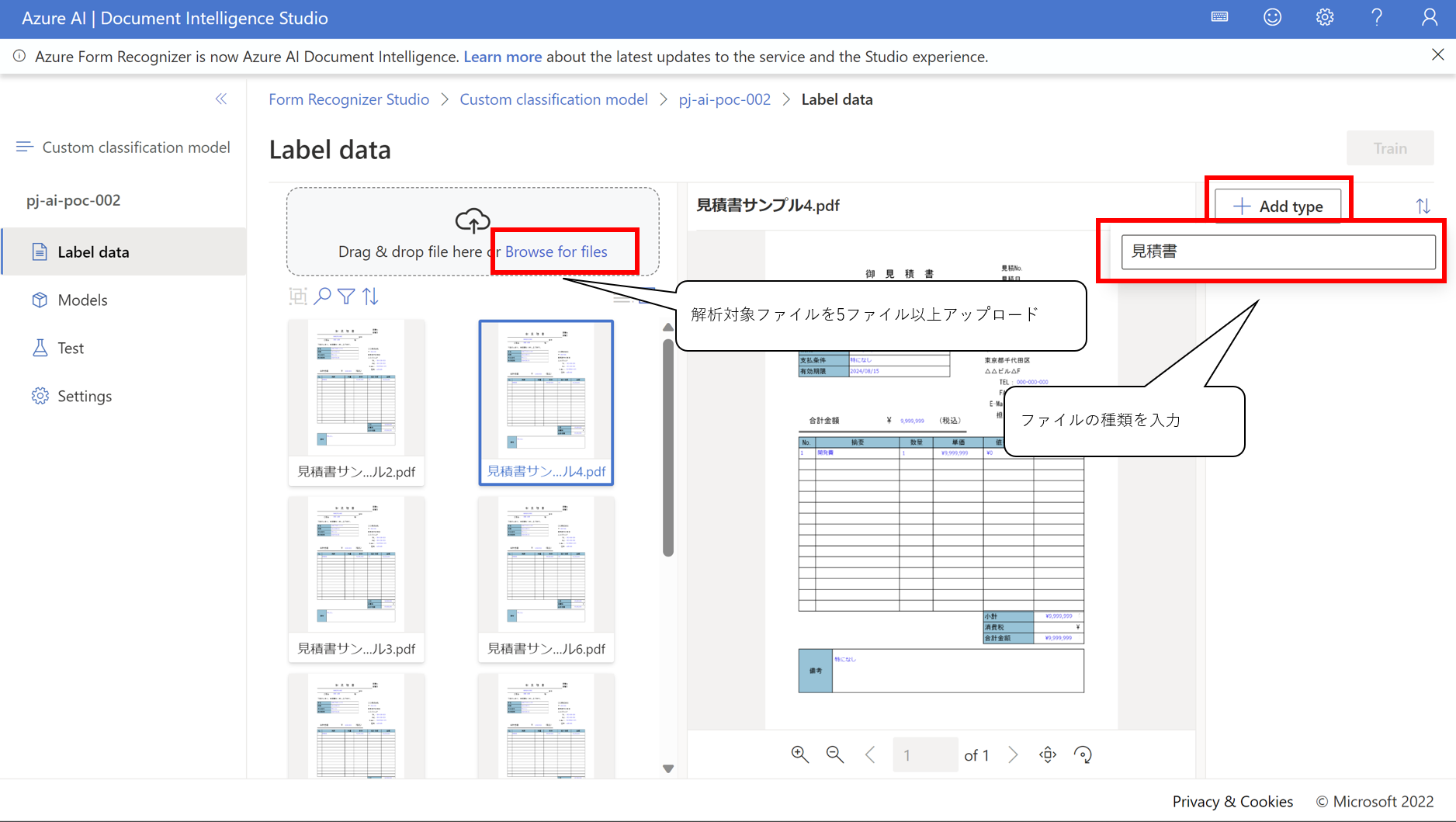
- 機械学習させるファイルをアップロードします※ファイルは5ファイル以上必要です
- Add Typeからドキュメントの種類を追加し、アップロードしたファイルがどの種類のドキュメントなのかを指定します
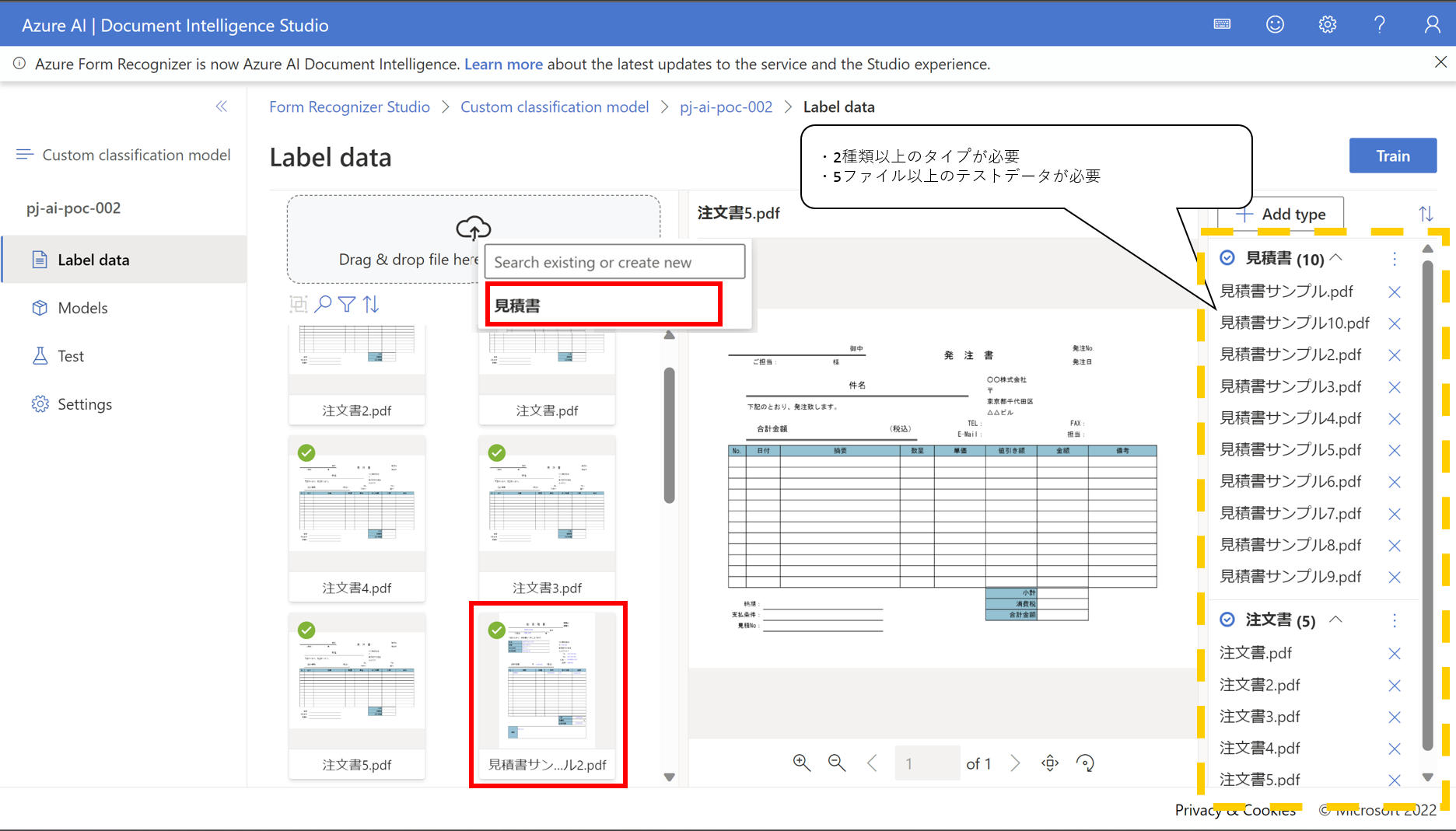
- Trainをクリックすると学習が開始されます
- モデルの作成が完了するとsucceseedと表示されます
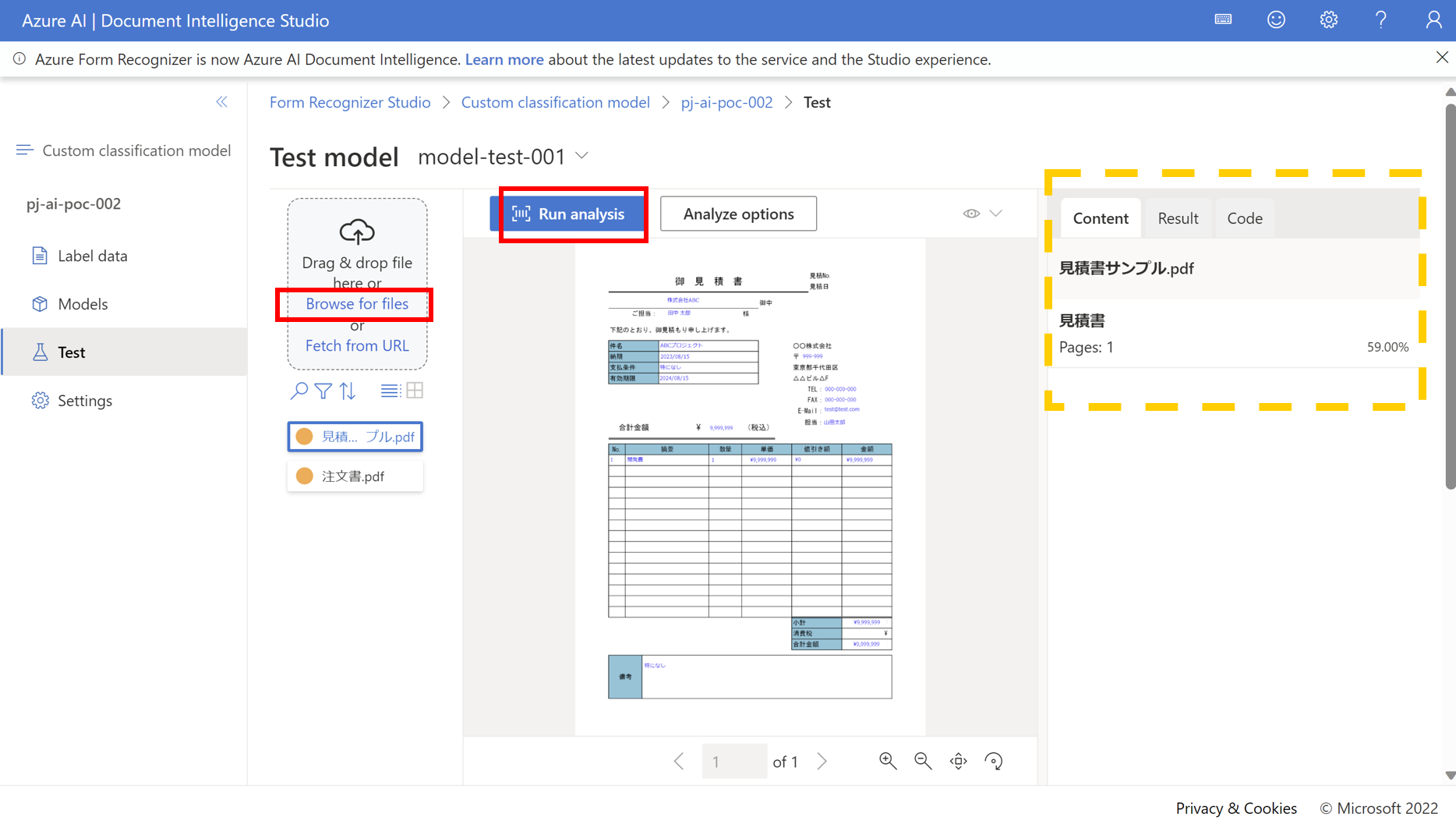
- TestタブでRun analysisをクリックすると作成したモデルでテストをすることができます
実行すると指定したファイルがどの種類のドキュメントに近いのかが、パーセンテージで表示することができます。
料金
基本的には、読み取るページ数に応じて、料金が発生。
- ※従量課金プランの場合の料金
- ※東日本リージョンの場合の料金
| インスタンス | ドキュメントの種類 | 料金 |
|---|---|---|
| Free | All | 1 か月あたり 0 から 500 ページが無料 |
| S0 | Read | 0-1 百万ページ - 1,000 ページあたり $1.50、百万ページ以上 - 1,000 ページあたり $0.60 |
| S0 | All Prebuilt Models: Document, Layout, Receipt, Invoice, ID, W-2, 1098 Tax forms, Health insurance card, Contract. | 1,000 ページあたり $10 |
| S0 | Custom classification | 1,000 ページあたり $3 |
| S0 | Custom extraction | 1,000 ページあたり $50 |
| S0 | Add-On2 | 1,000 ページあたり $6 |
| S0 | Query Fields | 1,000 ページあたり $10 |
主な制限事項
サポートされているファイルの種類
PDF、JPEG/JPG、PNG、BMP、TIFF、Officeファイル、HTMLファイルがサポートされています。
-
ドキュメント上は使用するモデルによってサポート可能なOfficeファイルの拡張子が異なる表記になっていますが
- 事前組込みモデルの場合: Word (DOCX)、Excel (XLS)、PowerPoint (PPT)
- カスタムモデルの場合: Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)
-
使用するモデルによってHTMLファイルのサポート内容が異なります
- 事前組込みモデルの場合: HTMLはサポート対象
- カスタムモデルの場合: HTMLはサポート対象外
-
Officeファイルの場合使用できるAPIが限られています
事前組込みモデル
| モデル | 画像: | Microsoft Office: | |
|---|---|---|---|
| **** | **** | jpeg/jpg、png、bmp、tiff、heif | Word (docx)、Excel (xls)、PowerPoint (ppt)、HTML |
| Read | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ (2024-02-29-preview、2023-10-31-preview、およびそれ以降) |
| General Document | ✔ | ✔ | |
| Prebuild | ✔ | ✔ | |
| Custom extraction | ✔ | ✔ | |
| Custom classification | ✔ | ✔ | ✔ |
カスタムモデル
| モデル | 画像: | Microsoft Office: | |
|---|---|---|---|
| **** | **** | jpeg/jpg、png、bmp、tiff、heif | Word (docx)、Excel (xlsx)、PowerPoint (pptx) |
| Read | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ (2024-02-29-preview、2023-10-31-preview、およびそれ以降) |
| General Document | ✔ | ✔ | |
| Prebuild | ✔ | ✔ | |
| Custom extraction | ✔ | ✔ | |
| Custom classification | ✔ | ✔ | ✔ |
クォータ上限
主なクォータ制限は以下の通りです。
| クォータ | Free (F0)1 | Standard (S0) |
|---|---|---|
| 1 秒あたりのトランザクション数の制限 | 1 | 15 (既定値) |
| ドキュメントの最大サイズ | 4 MB | 500 MB |
| ページの最大数 (分析) | 2 | 2000 |
| ラベル ファイルの最大サイズ | 10 MB | 10 MB |
| OCR json 応答の最大サイズ | 500 MB | 500 MB |
| Compose モデルの制限 | 5 | 200 (既定値) |
S0プランであれば、利用するのに十分なクォータが確保されていると言えるでしょう。
上記以外のクォータ制限については以下をご確認ください。
参考ドキュメント
おわりに
この記事では、AzureのOCRサービス「Document Intelligence」について紹介しました。
本記事が、AIを学習するエンジニアの参考になれば幸いです。
お問合せフォーム