はじめに
2025年05月20日からAzure AI Foundry Agent Serviceが一般提供が開始されました。
この記事では、Azure AI Foundry Agent ServiceのSDKについて紹介します。
GitHub: azure-sdk-for-python
Azure公式ドキュメント: azure-sdk-for-python
Azure公式ドキュメント: azure-sdk-for-python: readme
Azure AI Foundry Agent Serviceとは
Azure AI Foundry Agent Serviceは、AI エージェントの構築・管理ができるAzureのマネージドサービスです。
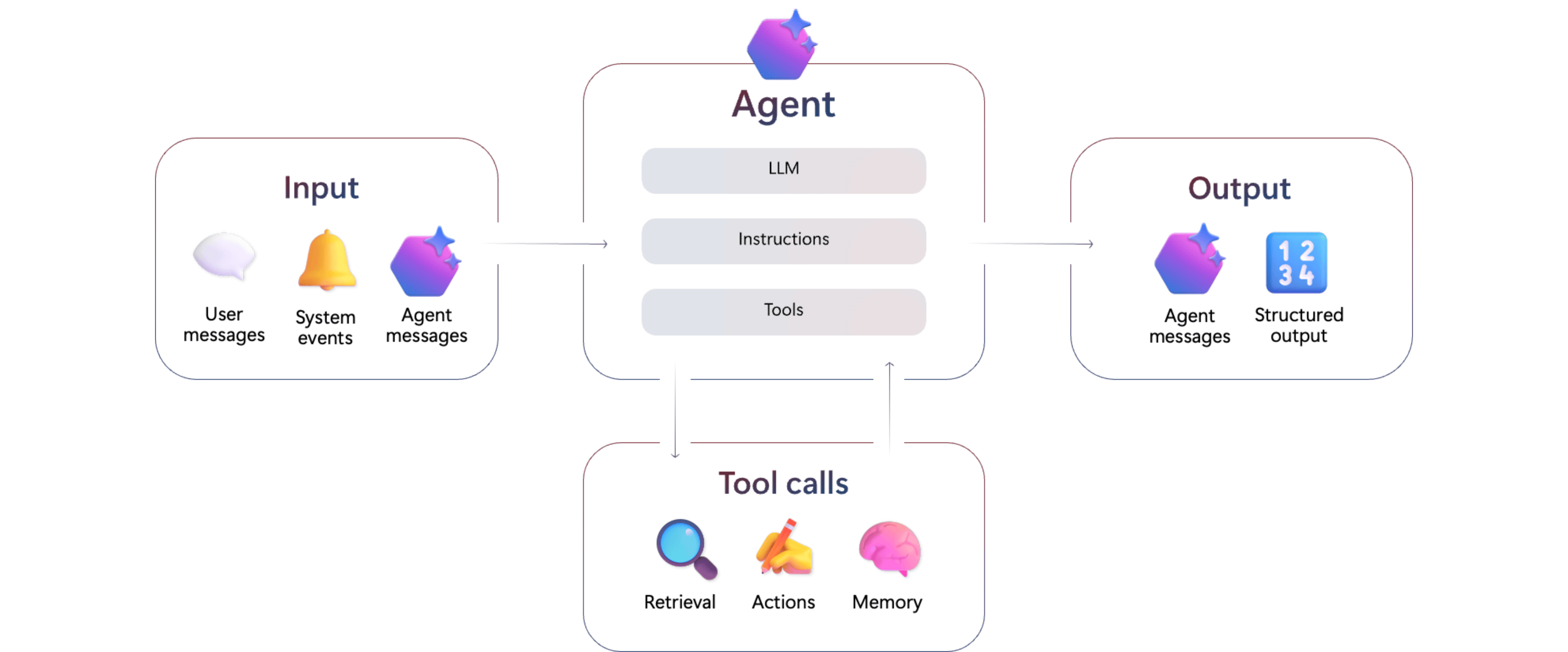
Azure AI Foundry Agent Serviceは、以下のような機能を提供しています。
- AI Foundry PortalやAzure AI Foundry SDKを使って、エージェントの構築、管理が可能
- 複数のAIエージェントを組み合わせるマルチエージェントの構築が可能
- A2A(Agent2Agent)、MCP(Model Context Protocol) などの業界標準プロトコルをサポート
- スレッドによるステートフルAPIをサポートしており、クライアントアプリ側での対話履歴の保持が不要
Azure AI Foundry Agent Service のセットアップパターン
Azure AI Foundry Agent Service には、以下の2つのセットアップパターンがあります。
1. Basic setup(基本セットアップ)
Agent Serviceで使用するデータをMicrosoftのマネージドリソース上に保持させる方法です。
通常、AzureでRAGアーキテクチャを構築する場合、Azure AI Searchなど高額なリソースを作成する必要がありますが、Basic setupを使用すれば、リソースの用意が不要なのでコストを下げることができます。
- メリット: ユーザー側はAgent Service以外のリソースの準備が不要で、ランニングコストが低い
- デメリット: プライベートネットワーク対応やアクセス制御などのカスタマイズはできない
2. Standard setup(標準セットアップ)
ユーザー独自のAzureリソースを使用して、より詳細な制御する方法です。
以下のリソースをマネージドから独自リソースに変更することができます。
- アップロードされたファイルは自分のAzure Storage Account上に保存
- ベクトルデータは自分のAzure AI Searchに保存
- スレッド(会話履歴)は自分のAzure Cosmos DBに保存
- ネットワークはパブリックとプライベート(独自VNet持ち込み)両方対応
- カスタマーマネージドキー(CMK):データの暗号化とセキュリティ
Standard setupのメリット、デメリットは以下の通りです。
-
メリット: プライベートネットワークやアクセス制御の実装、構築済みの既存のベクターインデックスのデータを使用したい場合などユーザー個別の要件に対応できる
-
デメリット: 独自のリソースの準備が必要で、独自リソース分のランニングコストも増加
Threads
ユーザーとAIアシスタント間の対話をOpenAIサーバ側で永続的に保存する機能です。
従来のCompletion APIではクライアント側から過去の会話履歴を毎回送信する必要がありますが、 一方、スレッドを使用すると、Azure OpeaAIサーバ側に会話履歴が保存されているので、クライアント側では情報を保存する必要がなく、ステートレスにすることができます。
スレッドはAzure Cosmos Database上に保存されます。
Messages
スレッド内の個々のユーザーとエージェントの個々の対話内容です。
Messagesはエージェントまたはユーザーが作成します。
テキストやファイルを含めることができ、リストとしてスレッド内に保存されます。
Runs
スレッド上でエージェントを実行する操作のことです。
エージェントはスレッドのメッセージと自身の設定に基づいてタスクを処理し、必要に応じてモデルやツールを呼び出すことができます。
Runの中でエージェントは新たなメッセージ(応答)をスレッドに追加する。
ツール
Agent Serviceでタスクを実行するために外部環境と連携する「ツール」が用意されています。
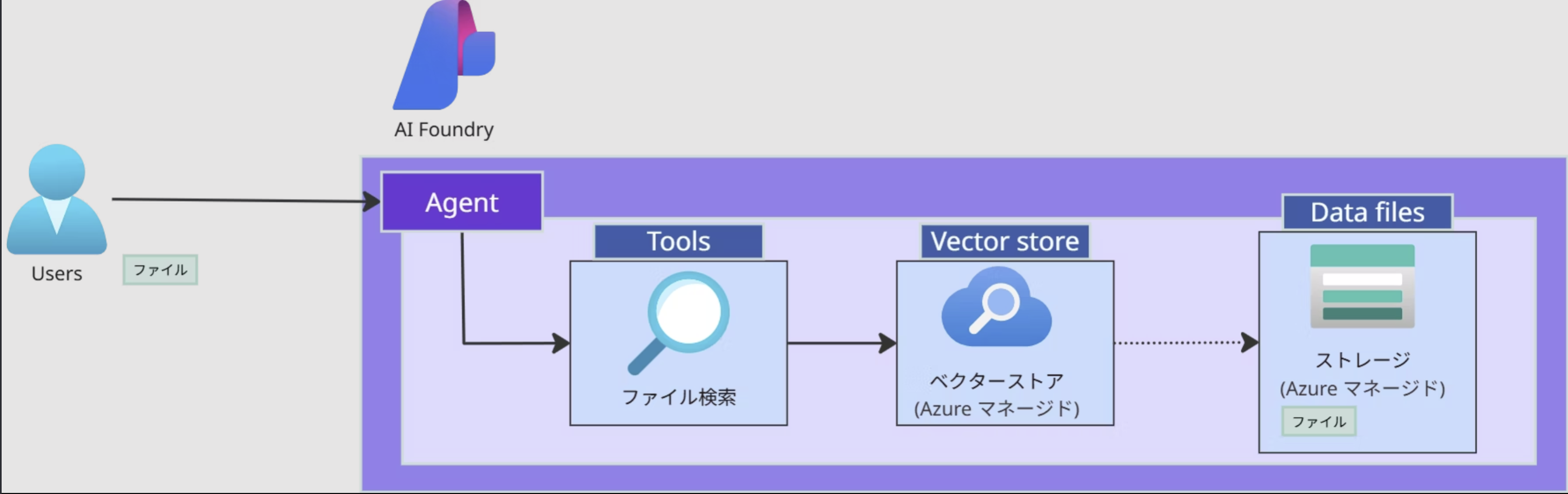
ファイル検索ツール
ファイル検索ツールはユーザーがAI Foundryにアップロードしたドキュメントを使って、ベクターストアによるRAGアーキテクチャを構築し、モデルに存在しない知識について回答させる手法です。
RAGアーキテクチャを構築する場合、Azure Storage AccountやAzure AI Searchなどのドキュメントファイルやベクトルデータの保存先が必要ですが、Agent ServiceではMicrosoftのマネージドのストレージやベクターストアが事前に用意されているので、ユーザーはそれらを用意する必要がありません。
Azure AI Agent ServiceのAPIを使ってドキュメントファイルをアップロードするだけで、RAGアーキテクチャを構築できます。
サポート対象ファイル
以下の通り、Markdown Tableでまとめた。
| File Format | MIME Type |
|---|---|
| .c | text/x-c |
| .cs | text/x-csharp |
| .cpp | text/x-c++ |
| .doc | application/msword |
| .docx | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| .html | text/html |
| .java | text/x-java |
| .json | application/json |
| .md | text/markdown |
| application/pdf | |
| .php | text/x-php |
| .pptx | application/vnd.openxmlformats-officedocument.presentationml.presentation |
| .py | text/x-python |
| .py | text/x-script.python |
| .rb | text/x-ruby |
| .tex | text/x-tex |
| .txt | text/plain |
| .css | text/css |
| .js | text/javascript |
| .sh | application/x-sh |
| .ts | application/typescript |
料金
AI Agent Serviceの料金として、主に以下の2種類があります。
モデル料金
モデルの利用料金はAgentに設定しているモデルを使用した分、料金が発生します。
金額はAzure OpenAI Serviceのモデルの利用料金と同額になります。
ツール料金
Agent Serviceでタスクを実行するために外部環境と連携する「ツール」を利用する場合の料金は以下になります。
| サービス | 料金 | 備考 |
|---|---|---|
| ファイル検索ストレージ | $0.10/GB/日 | 1GBまで無料※自動削除の仕組みがないので、ファイルはユーザーが明示的に削除する必要あり |
| コードインタープリタ | $0.03/セッション | |
| Computer Use入力トークン | $3/1Mトークン | |
| Computer Use出力トークン | $12/1Mトークン |
Azure公式ドキュメント: Azure AI Agent Service価格
Azure公式ドキュメント: Azure AI Foundry価格
制限・制約事項
AI Agent Serviceでは以下のような制限・制約があります。
| 項目 | 制限内容 | 備考 |
|---|---|---|
| エージェントの最大ファイル数 | 10,000 | |
| エージェント・ファインチューニング用の最大ファイルサイズ | 512 MB | |
| エージェントのアップロードファイル全体の最大容量 | 200 GB | |
| エージェントのトークン上限 | 2Mトークン | |
| Azureサブスクリプション内の最大エージェント数 | リージョンごとに2,000,000 | 米国東部リージョン・東日本リージョンで200万 |
| スレッドの最大ファイル数 | 10,000 | |
| スレッド内メッセージ数 | 制限なし | 削除ポリシーあり |
| メッセージ削除ポリシー | AUTO / LAST_MESSAGES | AUTO: コンテキスト長内で自動削除LAST_MESSAGES: 最新メッセージのみ保持 |
データの保持
- Foundry Agent Service API で使用されるデータ(スレッド、メッセージ、およびRUNなど)はセキュリティで保護された Microsoft が管理するストレージアカウントに格納される
- データの格納先のリージョンはAzure AI Foundry Agent Service エンドポイントと同じリージョンに格納される
- データは Microsoft によってモデルのトレーニングに使用されない
- 使用されているすべてのデータは、明示的に削除しない限り、このシステムに保持される
- Microsoftのマネージドのリソースにデータを保持させたくない場合は、Statndard agentという自分のAzureリソースにデータを保存する構成を取る必要がある(別途リソース使用分の料金が発生)
- Basic setupの場合、現状、どれぐらいの容量のファイルがアップロードされているかはAI Foundryのポータルサイトからは確認できず、確認するには、APIでファイル一覧を取得し、ファイルサイズを自前で測定する必要がある
Azure公式ドキュメント: Standard Agent Setup
Azure公式ドキュメント: F&Q
Azure公式ドキュメント: AI Agent Service制限事項
Azure AI Fondry Agent Serviceの利用方法
プロジェクトを作成
- Azure AI FoundryのトップページからCreate new
- 作成するリソースのタイプを選択
- 以下の2種類がある。本手順ではAzure AI Foundry resourceを選択する
-「Azure AI Foundry resource」は、すでに提供されている高性能LLMや業界特化モデルをサーバーレスで手軽に呼び出す
API プラットフォーム- 「AI hub resource」は、Azure ML の機能をフル活用して「自前モデルのトレーニング・ホスティング・デプロイ」まで行う
Agentとのチャットを開く
- Agents playgroundからAgentとのチャット画面を開く
- 使用するモデルを選択する。
REST APIの実行結果
スレッド内のメッセージの取得時のレスポンス(※SDKだと azure.ai.agents.models._patch.ThreadMessage クラス)から取得することできます。
contentの中に text部にある 【4:1†source】という文字が参照したファイル名に対応する置換文字列となります。
annotations 配下にどの置換文字列がどのファイル名に対応するかが識別できます。
実際のファイル名は file_id から取得が必要となります。
{
"id": "msg_hogehoge",
"object": "thread.message",
"created_at": 1749187901,
"assistant_id": "asst_hogehoge",
"thread_id": "thread_hogehoge",
"run_id": "run_hogehoge",
"role": "assistant",
"content": [
{
"type": "text",
"text": { "value": "このドキュメントにはhogehogeと書いてあります【4:1†source】。" },
"annotations": [
{
"type": "file_citation",
"text": "【4:1†source】",
"start_index": 331,
"end_index": 343,
"file_citation": { "file_id": "assistant-hogehoge" }
}
]
}
],
"attachments": [],
"metadata": {}
}
サンプルコード
以下のコードはAzure SDK使って、Azure AI Foundry Agent ServiceのAgentとThreadを使って、対話するサンプルコードです。
通常のリクエストと、ストリーミングでのリクエストの2種類を用意しています。
import asyncio
import os
from azure.ai.projects.aio import AIProjectClient
from azure.identity.aio import DefaultAzureCredential
from azure.ai.agents.models import (
TruncationObject, TruncationStrategy,
ThreadMessageOptions,
MessageRole, MessageInputTextBlock,
)
async def main():
PROJECT_ENDPOINT = "Azure AI Fonudryのプロジェクのエンドポイント"
AGENT_ID = "エージェントID"
MODEL_ID = "モデルID"
# エージェント全体の出力を決めるシステムインストラクションの設定
INSTRUCTIONS = "日本語で会話を行うAIエージェントです。ユーザーの質問に対して、適切な回答を提供します。"
# スレッドのRUN単位でのエージェントの出力を決める追加のインストラクション
ADDITTIONAL_INSTRUCTIONS = "会話相手が子供であることを考慮して、フランクに応答してください。"
# エージェントの追加メッセージとパラメータ
temperature = 1.0
top_p = 0.1
max_prompt_tokens = 16384
max_completion_tokens = 4096
polling_interval = 2
response_format = "auto" # フォーマットは現状autoのみ
last_messages = 4
# Projectクライアントの作成
# noinspection PyTypeChecker
project_client = AIProjectClient(
endpoint=PROJECT_ENDPOINT,
credential=DefaultAzureCredential()
)
# エージェント取得
agent_client = await project_client.agents.get_agent(agent_id=AGENT_ID)
agent_client.instructions = INSTRUCTIONS
# スレッド作成
thread = await project_client.agents.threads.create()
# スレッドにメッセージを追加
contents = [
MessageInputTextBlock(
{
"type": "text",
"text": "私の名前はジョンです"
}
)
]
message = await project_client.agents.messages.create(
thread_id=thread.id,
role=MessageRole.USER,
content=contents,
)
# トランケーション戦略の設定
truncation_strategy = TruncationObject(
type=TruncationStrategy.LAST_MESSAGES,
last_messages=last_messages
)
# 会話を追加メッセージスレッドの最後列に追加
additional_messages = [
{
"role": MessageRole.AGENT,
"content": "こんにちは!"
},
{
"role": MessageRole.USER,
"content": "私の名前をおぼえていますか?"
}
]
additional_thread_messages = []
for msg in additional_messages:
thread_message = ThreadMessageOptions(
role=msg.get("role", "user"),
content=msg.get("content", "")
)
additional_thread_messages.append(thread_message)
# RUN実行し、エージェントメッセージを送信
run = await project_client.agents.runs.create_and_process(
thread_id=thread.id,
agent_id=agent_client.id,
model=MODEL_ID,
additional_instructions=ADDITTIONAL_INSTRUCTIONS,
additional_messages=additional_thread_messages,
temperature=temperature,
top_p=top_p,
max_prompt_tokens=max_prompt_tokens,
max_completion_tokens=max_completion_tokens,
polling_interval=polling_interval,
response_format=response_format,
truncation_strategy=truncation_strategy
)
print(f"Run result: [{run}]")
print(
f"thread id: [{run.thread_id}], "
f"status: [{run.status}], "
f"incomplete details: [{run.incomplete_details}], "
f"cancelled: [{run.cancelled_at}], "
f"failed: [{run.failed_at}], "
f"last error: [{run.last_error}]"
)
print(f"Run result usage: [{run.usage}]")
# Threadのメッセージを降順に取得して表示
print("-----------------------------------------------------------------")
messages = project_client.agents.messages.list(thread_id=thread.id)
idx = 1
async for message in messages:
message_text_details = message.content[0].get("text", {})
text_value = message_text_details.get("value")
role = message.role.value
print(f"[{idx}]. Role: [{role}], Text: [{text_value}], message keys[{message.keys()}]")
idx += 1
print(f"-----------------------------------------------------------------\n")
# RUNをストリーミングで実行
print("Starting run streaming...")
stream = await project_client.agents.runs.stream(
thread_id=thread.id,
agent_id=agent_client.id,
model=MODEL_ID,
additional_instructions=ADDITTIONAL_INSTRUCTIONS,
additional_messages=additional_thread_messages,
temperature=temperature,
top_p=top_p,
max_prompt_tokens=max_prompt_tokens,
max_completion_tokens=max_completion_tokens,
response_format=response_format,
truncation_strategy=truncation_strategy
)
# ストリーミングで送信する場合
event_count = 0
async for event in stream.event_handler:
event_count += 1
# イベントの種類に応じて処理を分岐
# イベントの種類は以下の通り
# [thread.run.created]: RUN作成完了, data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
# [thread.run.queued]: QUEUEの送信完了 data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
# [thread.run.in_progress]: RUNの実行中, data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
# [thread.run.step.created]: STEPの作成, data:[<class 'azure.ai.agents.models._models.RunStep'>]
# [thread.run.step.in_progress]: STEPの実行中, data:[<class 'azure.ai.agents.models._models.RunStep'>]
# [thread.message.created]: MESSAGEの作成完了, data:[<class 'azure.ai.agents.models._patch.ThreadMessage'>]
# [thread.message.in_progress]: MESSAGEの処理中, data:[<class 'azure.ai.agents.models._patch.ThreadMessage'>]
# [thread.message.delta]: ストリーミング中のメッセージの一部を送信, data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
# [thread.message.completed]: ストリーミングのメッセージ送信完了通知, data:[<class 'azure.ai.agents.models._patch.ThreadMessage'>]
# [thread.run.step.completed]: STEPの完了, data:[<class 'azure.ai.agents.models._models.RunStep'>]
# [thread.run.completed]: RUNの完了, data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
# [done]: ストリーミングの完了通知, data:[<class 'str'>]
event_status = event[0]
event_data = event[1]
print(f"[{event_count}], Event: type[{type(event)}] stats:[{event_status}], data:[{type(event_data)}]")
# ストリーミング中のメッセージの一部を表示
if event_status == "thread.message.delta":
content = event_data.delta.content
text_value = content[0].get("text", {}).get("value", "")
print(f" Delta message content: [{text_value}]")
# ストリームのの完了後のメッセージの全体を表示
elif event_status == "thread.message.completed":
content = event_data.content
text_value = content[0].get("text", {}).get("value", "")
print(f" Message Completed Content [{event_data.content}]")
# Runの実行完了後のトークン使用量を表示
elif event_status == "thread.run.completed":
usage = event_data.usage
print(f" Run completed, Usage: [{usage}]")
elif event_status == "done":
print(f" Stream completed.{event_data}")
print("Run streaming completed.")
await project_client.close()
if __name__ == "__main__":
asyncio.run(main())
Run result: [{'id': 'run_hogehoge', 'object': 'thread.run', 'created_at': 1753512238, 'assistant_id': 'asst_hogehoge', 'thread_id': 'thread_hogehoge', 'status': 'completed', 'started_at': 1753512238, 'expires_at': None, 'cancelled_at': None, 'failed_at': None, 'completed_at': 1753512239, 'required_action': None, 'last_error': None, 'model': 'gpt-4o-mini', 'instructions': ' 会話相手が子供であることを考慮して、フランクに応答してください。', 'ツール': [{'type': 'file_search'}], 'tool_resources': {}, 'metadata': {}, 'temperature': 1.0, 'top_p': 0.1, 'max_completion_tokens': 4096, 'max_prompt_tokens': 16384, 'truncation_strategy': {'type': 'last_messages', 'last_messages': 4}, 'incomplete_details': None, 'usage': {'prompt_tokens': 702, 'completion_tokens': 26, 'total_tokens': 728, 'prompt_token_details': {'cached_tokens': 0}}, 'response_format': 'auto', 'tool_choice': 'auto', 'parallel_tool_calls': True}]
thread id: [thread_hogehoge], status: [RunStatus.COMPLETED], incomplete details: [None], cancelled: [None], failed: [None], last error: [None]
Run result usage: [{'prompt_tokens': 702, 'completion_tokens': 26, 'total_tokens': 728, 'prompt_token_details': {'cached_tokens': 0}}]
-----------------------------------------------------------------
[1]. Role: [assistant], Text: [うん、ジョンだよね!覚えてるよ!他に何か話したいことある?], message keys[dict_keys(['id', 'object', 'created_at', 'assistant_id', 'thread_id', 'run_id', 'role', 'content', 'attachments', 'metadata'])]
[2]. Role: [user], Text: [私の名前をおぼえていますか?], message keys[dict_keys(['id', 'object', 'created_at', 'assistant_id', 'thread_id', 'run_id', 'role', 'content', 'attachments', 'metadata'])]
[3]. Role: [assistant], Text: [こんにちは!], message keys[dict_keys(['id', 'object', 'created_at', 'assistant_id', 'thread_id', 'run_id', 'role', 'content', 'attachments', 'metadata'])]
[4]. Role: [user], Text: [私の名前はジョンです], message keys[dict_keys(['id', 'object', 'created_at', 'assistant_id', 'thread_id', 'run_id', 'role', 'content', 'attachments', 'metadata'])]
-----------------------------------------------------------------
Starting run streaming...
[1], Event: type[<class 'tuple'>] stats:[thread.run.created], data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
[2], Event: type[<class 'tuple'>] stats:[thread.run.queued], data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
[3], Event: type[<class 'tuple'>] stats:[thread.run.in_progress], data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
[4], Event: type[<class 'tuple'>] stats:[thread.run.step.created], data:[<class 'azure.ai.agents.models._models.RunStep'>]
[5], Event: type[<class 'tuple'>] stats:[thread.run.step.in_progress], data:[<class 'azure.ai.agents.models._models.RunStep'>]
[6], Event: type[<class 'tuple'>] stats:[thread.message.created], data:[<class 'azure.ai.agents.models._patch.ThreadMessage'>]
[7], Event: type[<class 'tuple'>] stats:[thread.message.in_progress], data:[<class 'azure.ai.agents.models._patch.ThreadMessage'>]
[8], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [う]
[9], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [ん]
[10], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [、]
[11], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [君]
[12], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [の]
[13], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [名前]
[14], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [は]
[15], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [ジョ]
[16], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [ン]
[17], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [だ]
[18], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [よ]
[19], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [ね]
[20], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [!]
[21], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [他]
[22], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [に]
[23], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [何]
[24], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [か]
[25], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [話]
[26], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [した]
[27], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [い]
[28], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [こと]
[29], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [が]
[30], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [ある]
[31], Event: type[<class 'tuple'>] stats:[thread.message.delta], data:[<class 'azure.ai.agents.models._patch.MessageDeltaChunk'>]
Delta message content: [?]
[32], Event: type[<class 'tuple'>] stats:[thread.message.completed], data:[<class 'azure.ai.agents.models._patch.ThreadMessage'>]
Message Completed Content [[{'type': 'text', 'text': {'value': 'うん、君の名前はジョンだよね!他に何か話したいことがある?', 'annotations': []}}]]
[33], Event: type[<class 'tuple'>] stats:[thread.run.step.completed], data:[<class 'azure.ai.agents.models._models.RunStep'>]
[34], Event: type[<class 'tuple'>] stats:[thread.run.completed], data:[<class 'azure.ai.agents.models._models.ThreadRun'>]
Run completed, Usage: [{'prompt_tokens': 719, 'completion_tokens': 26, 'total_tokens': 745, 'prompt_token_details': {'cached_tokens': 0}}]
[35], Event: type[<class 'tuple'>] stats:[done], data:[<class 'str'>]
Stream completed.[DONE]
Run streaming completed.
Python-SDKの各クラスについて
azure.ai.agents.aioパッケージ
AIProjectClient
Azure AI Foundry Services のプロジェクトに非同期でアクセスするためのクライアントクラスです。
Agentの作成や、スレッドの作成、ベクターストア作成などFoundry上のプロジェクトへの主な操作はこのクラスを介して実行することができます。
インスタンス生成例
# AIProjectClientの作成
endpoint = "https://<ai-services-account-name>.services.ai.azure.com/api/projects/<project_name>"
credential = DefaultAzureCredential()
project_client = AIProjectClient(endpoint, credential)
# AIProjectClientのagentsフィールドはAgentsClient型で、AgentやVectorStoreへの操作が可能
# Agentを取得
agent = await self.project_client.agents.get_agent(agent_id="hogehoge")
# Agentを更新
agent = await self.project_client.agents.update_agent(
agent_id="hogehoge",
ツール=ツール.definitions,
tool_resources=tool_resources
)
# スレッドを作成
thread = await self.project_client.agents.threads.create()
# スレッドを取得
thread = await self.project_client.agents.threads.get(thread_id="hogehoge")
AgentsClient
Azure AI Foundry Agents Serviceのエージェントの管理・実行用非同期クライアントクラスです。
Agent、Threadの作成、Runの実行、Tool実行、ベクターストアの作成など関する操作はこのクラスで行います。
TruncationObjectのインスタンス生成例
from azure.ai.agents.aio import AgentsClient
from azure.identity.aio import DefaultAzureCredential
client = AgentsClient(
endpoint="https://your-resource-endpoint",
credential=DefaultAzureCredential()
)
主なメソッド
- init(endpoint, credential, **kwargs): クライアント初期化
- create_agent(…): エージェントの新規作成
- update_agent(…): 作成済みエージェントのツール設定などの変更を行う
- delete_agent(agent_id): エージェントの削除
- enable_auto_function_calls(ツール, max_retry=10): 自動関数ツール呼び出し設定
- create_thread_and_run(…): スレッド新規作成とRUNの実行を行う
- create_thread_and_process_run(…): スレッド新規作成+自動実行+自動ツール呼び出し+完了までポーリング
azure.ai.agents.modelsパッケージ
Agent
Agentは、エージェントを示すデータモデルクラスです。
データモデルなので、ロジックがなく、メソッドはありません。
| フィールド名 | 型 | 説明 | 例 |
|---|---|---|---|
id |
str |
識別子 | "asst_hogehoge" |
object |
str |
オブジェクト種別(固定値) | "assistant" |
created_at |
datetime (UNIX秒) |
作成日時 | 1748856911 |
name |
str |
エージェントの名前 | "agent-hogehoge-001" |
description |
str |
エージェントの説明 | "営業資料検索用エージェント" |
model |
str |
使用モデルのID | "gpt-4o-mini" |
instructions |
str |
システム命令文 | "ユーザーの質問には必ず簡潔に答えること" |
ツール |
list[ToolDefinition] |
使用するツールのリスト | [{"type": "file_search"}, {"type": "code_interpreter"}] |
tool_resources |
ToolResources |
ツールリソースの設定 | {"file_search": {"vector_store_ids": ["vs_hogehoge"]}} |
temperature |
float |
出力のランダム性(0〜2) | 0.7 |
top_p |
float |
出力の確率分布割合(0〜1) | 1.0 |
response_format |
str |
応答形式 | "auto" |
metadata |
dict[str, str] |
任意のメタデータ(16個まで) | {"purpose": "doc_search", "team": "sales"} |
ThreadMessage
ThreadMessageは、スレッド内のメッセージを示すデータクラスです。
| フィールド名 | 型 | 説明 | 例 |
|---|---|---|---|
id |
str |
メッセージの識別子 | "msg_QG9FuU9tEJOr0Fr7ya6quu6X" |
object |
str |
オブジェクト種別(固定値) | "thread.message" |
created_at |
datetime (UNIX秒) |
作成日時 | 1749620079 |
assistant_id |
str |
メッセージ生成元のアシスタントID | "asst_hogehoge" |
thread_id |
str |
紐づくスレッドID | "thread_hogehoge" |
run_id |
str |
紐づく実行ランID | "run_KgwGupSt259ICU1TwaxiW9d0" |
role |
str |
メッセージの送信者ロール("assistant" or "user") |
"assistant" |
content |
list[dict] |
メッセージ本文。テキストやファイル等 | [{"type": "text", "text": {"value": "私は、AIアシスタントです。", "annotations": []}}] |
attachments |
list |
添付ファイル情報(未使用時空リスト) | [] |
metadata |
dict[str, str] |
任意のメタデータ | {} |
MessageInputContentBlock
メッセージ作成時の単一コンテンツブロックを定義する基底クラスです。
typeフィールドによってテキスト、画像ファイル、外部画像URLなどを判別します
直接このクラスは使用せず、以下のサブクラスを使用することが推奨されています。
- MessageInputTextBlock
- MessageInputImageUrlBlock
- MessageInputImageFileBlock
メッセージブロックのインスタンス生成例
message = MessageInputTextBlock(
{
"type": "text",
"text": "Hello"
}
)
message = MessageInputImageUrlBlock(
{
"type": "image_url",
"image_url": {
"url": "https://hogehoge.com/hoge.jpg"
}
}
)
ThreadMessageOptions
ThreadMessageOptionsはスレッド内の個々のメッセージを示すデータクラスです。
インスタンス生成
# str型でロールとコンテンツを設定する場合
thread_message_options = ThreadMessageOptions(
role="user",
content="hello"
)
# MessageRoleとlist[MessageInputContentBlock]でロールとコンテンツを設定する場合
thread_message_options = ThreadMessageOptions(
role=MessageRole.USER,
content=[
message = MessageInputTextBlock(
{
"type": "text",
"text": "Hello"
}
)
]
)
GitHub: ThreadMessageOptions
Azure公式ドキュメント: ThreadMessageOptions
TruncationObject
TuncationObjectはメッセージ削除ポリシーを設定します。
- AUTO: トークン数が設定されているコンテキストウィンドウを超過した場合に自動削除
- LAST_MESSAGES: 指定した数の最新メッセージのみ保持
インスタンスの生成
# AUTO: 設定されているコンテキストウィンドウを超過した場合に自動削除
truncation_strategy = TruncationObject(
type=TruncationStrategy.AUTO
)
# LAST_MESSAGES: 最後のlast_messages数のメッセージを保持する
truncation_strategy = TruncationObject(
type=TruncationStrategy.LAST_MESSAGES,
last_messages=2
)
MessageContent
Thread内のメッセージコンテンツを示すすデータクラス。 このクラスは抽象クラスなので、直接このクラスを使用するのではなく、以下のサブクラスが使用されます。
- MessageTextContent : スレッド内のテキストメッセージ
- MessageImageFileContent : スレッド内の画像ファイルを含むメッセージ
# MessageTextContentの場合の中身
# 【6:11†source】は生成したコンテンツがFile Search Toolで検索にヒットしたファイルのうち、どのファイルをもとに生成したかを示す
{
'type': 'text',
'text': {
'value': 'Hello【6:11†source】。',
'annotations': [
{
'type': 'file_citation',
'text': '【6:11†source】',
'start_index': 85,
'end_index': 98,
'file_citation': {
'file_id': 'assistant-hogehoge'
}
}
]
}
}
MessageTextAnnotation
テキストスレッドメッセージコンテンツのアノテーション(注釈)を表現する抽象クラス。
直接このクラスを使用するのではなく、以下のサブクラスを使用されます。
- MessageTextFileCitationAnnotation : File Search Toolを使用した際に、検索にヒットしたファイルの情報を所持する
- MessageTextFilePathAnnotation : Code Interpreter Toolを使用してファイルを生成した際のファイル参照に使用される。
- MessageTextUrlCitationAnnotation : Bing Grounding Toolを使用してインターネット検索を行った際に生成される。
# MessageTextFileCitationAnnotationの場合の中身
{
'type': 'file_citation',
'text': '【6:11†source】',
'start_index': 85,
'end_index': 98,
'file_citation': {'file_id': 'assistant-hogehoge'}
}
RunsOperations
RUNを実行するためのクラスです。
非同期処理に対応しており、ツール呼び出しやストリーミング機能をサポートしています。
RunsOperationsのフィールド
_function_tool: AsyncFunctionTool型のツール実行機能(デフォルト: 空のセット)_function_tool_max_retry: int型のツール実行最大リトライ回数(デフォルト: 0)
メソッド
create(thread_id: str, ...) -> ThreadRun: エージェントスレッドの新しい実行を作成- 実行するだけなのでツール呼び出しが必要な場合、手動でsubmit_tool_outputs()を呼ぶ必要がある
- 実行完了の監視は別途実装が必要
create_and_process(thread_id: str, ...) -> ThreadRun: 実行を作成し、完了まで処理を監視- ツール呼び出しが発生した場合も自動的に処理
- 最終的な完了状態のThreadRunを返す
stream(thread_id: str, ...) -> AsyncAgentRunStream: エージェントスレッドのストリーミング実行を作成submit_tool_outputs(thread_id: str, run_id: str, ...) -> ThreadRun: ツール呼び出しの結果を送信submit_tool_outputs_stream(thread_id: str, run_id: str, ...) -> None: ツール出力をストリーミングで送信
ThreadRun
ThreadのRunを表すデータクラス。 Runの状態、設定、結果などの情報を管理する。
フィールド
-
id (str): API エンドポイントで参照可能な識別子 [必須]
-
object (Literal[“thread.run”]): オブジェクトタイプ(常に’thread.run’) [必須]
-
thread_id (str): 関連するスレッドのID [必須]
-
agent_id (str): 関連するエージェントのID [必須]
-
status (Union[str, RunStatus]): エージェントスレッド実行のステータス [必須]
- statusの値は “queued”, “in_progress”, “requires_action”, “cancelling”, “cancelled”, “failed”, “completed”, “expired” のいずれか
-
required_action (Optional[RequiredAction]): 実行継続に必要なアクションの詳細
-
last_error (RunError): 最後に発生したエラー [必須]
-
model (str): 使用するモデルのID [必須]
-
instructions (str): オーバーライドされたシステム指示 [必須]
-
ツール (List[ToolDefinition]): オーバーライドされた有効なツール [必須]
-
created_at (datetime.datetime): 作成時のUnixタイムスタンプ [必須]
-
expires_at (datetime.datetime): 有効期限のUnixタイムスタンプ [必須]
-
started_at (datetime.datetime): 開始時のUnixタイムスタンプ [必須]
-
completed_at (datetime.datetime): 完了時のUnixタイムスタンプ [必須]
-
cancelled_at (datetime.datetime): キャンセル時のUnixタイムスタンプ [必須]
-
failed_at (datetime.datetime): 失敗時のUnixタイムスタンプ [必須]
-
incomplete_details (IncompleteRunDetails): 不完全な実行の詳細 [必須]
-
usage (RunCompletionUsage): 実行に関する使用統計 [必須]
-
temperature (Optional[float]): サンプリング温度(デフォルト: 1)
-
top_p (Optional[float]): nucleus サンプリング値(デフォルト: 1)
-
max_prompt_tokens (int): 最大プロンプトトークン数 [必須]
-
max_completion_tokens (int): 最大完了トークン数 [必須]
-
truncation_strategy (TruncationObject): メッセージドロップ戦略 [必須]
-
tool_choice (AgentsToolChoiceOption): ツール呼び出し制御 [必須]
-
response_format (AgentsResponseFormatOption): レスポンス形式 [必須]
-
metadata (Dict[str, str]): 追加情報用のキー/値ペア(最大16個) [必須]
-
tool_resources (Optional[ToolResources]): 実行用ツールのオーバーライド
-
parallel_tool_calls (bool): 並列ツール実行の可否 [必須]
RunStatus
RunStatusは、エージェントのRunの状態を表す列挙型(Enum)です。
以下のステータスが定義されています。
| ステータス | 説明 |
|---|---|
QUEUED |
実行待ち状態 |
IN_PROGRESS |
実行中 |
REQUIRES_ACTION |
ツール出力など追加操作待ち |
CANCELLING |
キャンセル中 |
CANCELLED |
キャンセル完了 |
FAILED |
エラーなどで失敗 |
COMPLETED |
実行成功 |
EXPIRED |
タイムアウトや期限切れ |
(if run.status == RunStatus.FAILED:)などのように実装して、RUNの実行結果の判定に使用することができます。
ツール
ツールはエージェントが使用するツールの定義とリソース、実行ロジックの3つを共通化する抽象ツールクラスです。
-
抽象クラス(
ABC)+ジェネリクス(Generic[ToolDefinitionT])ABC: Pythonの抽象基底クラス(Abstract Base Class)の基底クラス。直接インスタンス化はできず、サブクラスでメソッドを実装してインスタンス生成するGeneric[ToolDefinitionT]: Generics は「型を後から与える」
-
エージェントに使わせるツールの共通インターフェース
-
エージェントが複数のツールを統一的に扱うためのベース
- 継承して具体的なツールを実装することが前提
- 3つの抽象メンバを持つため、継承クラスは必ずそれらを実装する必要あり
-
@property def definitions(self) -> List[ToolDefinitionT]- ツールの定義(仕様)をリスト形式で返す。
-
@property def resources(self) -> ToolResources- ツールが利用するリソース(例:APIキー、接続情報、外部サービスなど)を返す。
-
def execute(self, tool_call: Any) -> Any- ツールの実行処理。
tool_callは実行対象の呼び出し(関数名・引数セットなど)- 戻り値はツールの出力(APIレスポンス、処理結果など)
class ツール(ABC, Generic[ToolDefinitionT]):
"""
An abstract class representing a ツール that can be used by an agent.
"""
@property
@abstractmethod
def definitions(self) -> List[ToolDefinitionT]:
"""Get the ツール definitions."""
@property
@abstractmethod
def resources(self) -> ToolResources:
"""Get the ツール resources."""
@abstractmethod
def execute(self, tool_call: Any) -> Any:
"""
Execute the ツール with the provided ツール call.
:param Any tool_call: The ツール call to execute.
:return: The output of the ツール operations.
"""
ToolDefinition
エージェントが使用するツール定義の抽象クラスです。
typeフィールド(str型)に使用するツールが何のツールかをエージェントに伝える設定をしたり、ツールの細かい動作の実装などを定義します。
このクラスを直接使うのではなく、ツールごとに用意された以下のサブクラスを使用します。
AzureAISearchToolDefinitionAzureFunctionToolDefinitionBingCustomSearchToolDefinitionBingGroundingToolDefinitionCodeInterpreterToolDefinitionConnectedAgentToolDefinitionDeepResearchToolDefinitionMicrosoftFabricToolDefinitionFileSearchToolDefinitionFunctionToolDefinitionMCPToolDefinitionOpenApiToolDefinitionSharepointToolDefinition
ToolResource
ToolResources クラスは、各ツールが使う「外部リソース」をまとめて管理するためクラスです。
ToolResourcesについても使用するツールごとに接続するリソースクラスが用意されています。
例えば、ファイル検索ツールを使用する場合は、FileSearchToolResourceクラスに接続するベクターストアのIDを設定します。
FileSearchTool
FileSearchToolはAgent Serviceでファイル検索ツールを使用するときに使うクラスです。
# ファイル検索ツールのインスタンス生成
file_search_tool = FileSearchTool(vector_store_ids=["vector_store_hogehoge"])
# Agentにファイル検索ツールからツール定義情報(definitions)と接続リソース情報(resources)を渡します
project_client = AIProjectClient(endpoint, credential)
agent = project_client.agents.update_agent(
agent_id="agent_hogehoge",
ツール=file_search_tool.definitions,
tool_resources=file_search_tool.resources
)
FilePurpose
FilePurposeは、ファイルをAgent Serviceにアップロードする目的を定義した列挙型です。 以下の3つが定義されています。
| 値 | 用途の説明 | 代表的な使い道 |
|---|---|---|
AGENTS |
エージェントの入力ファイル | 例:コード、word,pptx,pdfなどのドキュメントファイル |
AGENTS_OUTPUT |
エージェントが出力した結果ファイル | 例:生成されたCSV、分析レポート、ログ |
VISION |
画像解析などビジョン系処理の入力ファイル | 例:画像ファイルなど |
VectorStoreFile
VectorStoreFileクラスは、ベクトルストアに添付されたファイルの詳細を表すデータモデルクラスです。
| フィールド名 | 型 | 説明 | 例 |
|---|---|---|---|
id |
str |
ファイルの一意識別子 | "file_hogehoge" |
object |
str |
オブジェクト種別(常に "vector_store.file") |
"vector_store.file" |
usage_bytes |
int |
ベクトルストアでの使用バイト数(元ファイルサイズと異なる場合あり) | 1048576 |
created_at |
datetime (UNIX秒) |
作成日時 | 1749620079 |
vector_store_id |
str |
添付先ベクトルストアID | "vs_hogehoge" |
status |
str |
ファイル状態("in_progress"、"completed"、"failed"、"cancelled") |
"completed" |
last_error |
dict or null |
最後に発生したエラー(エラーがなければ null) |
{"code": "server_error", "message": "An internal error occurred."} |
chunking_strategy |
dict |
ファイル分割戦略 | {"type": "static", "static": {"max_chunk_size_tokens": 800, "chunk_overlap_tokens": 400}} |
VectorStoreChunkingStrategyRequest
ベクトルストア内のデータを効率的に検索するために小さなまとまり(チャンク)に分割する際の分割方法(チャンキング戦略)を設定するクラスです。
Azure AI Fondry Agent Serviceのチャンキング戦略にはauto(デフォルト)とstaticの2種類の分割方法あります。
チャンキング戦略の2つのトークンパラメータ
max_chunk_size_tokens (最大チャンクサイズ)
-
用途: 1つのチャンクに含める最大トークン数を制限
-
例
元文書: [1000トークンの長い文書]
- チャンク1: [800トークン]
- チャンク2: [200トークン]
- 効果:
- 大きすぎる → 処理負荷増大
- 小さすぎる → 文脈の断片化で検索制度低下
chunk_overlap_tokens (チャンク重複)
-
用途: 隣接するチャンク間で共有するトークン数
-
例 (※簡略化のため、トークン数は仮の値を記載)
文書: "太郎は学校に行った。そこで友達の花子に会った。花子は図書館で本を読んでいた。"
max_chunk_size_tokens=20, chunk_overlap_tokens=10の場合:
- チャンク1: "太郎は学校に行った。そこで友達の花子に会った。" (20トークン)
- チャンク2: "そこで友達の花子に会った。花子は図書館で本を読んでいた。" (10トークン重複 + 10トークン新規)
「そこで友達の花子に会った。」の部分が重複することによって、両方のチャンクが「友達の花子に会った」という情報を保持しているので、どちらのチャンクからも適切な回答が得られる。
- 効果:
- 文脈の連続性確保: チャンク境界で情報が分断されることを防ぐ
- 検索漏れ防止: 境界付近の重要な情報を複数チャンクで保持
- 大きすぎる → 重複分のトークンコスト増加により処理負荷増大
- 小さすぎる → 文脈の断片化で検索制度低下
auto: デフォルトの戦略
デフォルトの設定に基づいて、自動的に分割する方法。
デフォルトではmax_chunk_size_tokens を 800、chunk_overlap_tokensを400で分割。
各チャンクは最大800トークンで、チャンク間には400トークンの重複が許容される。
# type: autoを指定
chunking_strategy = VectorStoreChunkingStrategyRequest(type="auto")
# JSON形式のマッピングから指定も可能
mapping = {"type": "auto"}
chunking_strategy = VectorStoreChunkingStrategyRequest(mapping)
static
ユーザーが、max_chunk_size_tokensと、chunk_overlap_tokensに任意の値を設定して分割する方法。
# type: staticを指定するときはVectorStoreStaticChunkingStrategyRequestを使用
VectorStoreStaticChunkingStrategyOptions(
max_chunk_size_tokens=max_chunk_size_tokens,
chunk_overlap_tokens=chunk_overlap_tokens
)
chunking_strategy = VectorStoreStaticChunkingStrategyRequest(
static=VectorStoreStaticChunkingStrategyOptions
)
参考
API仕様
- https://learn.microsoft.com/en-us/rest/api/aifoundry/aiprojects/
- https://learn.microsoft.com/en-us/rest/api/aifoundry/aiagents/
SDK
-
https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/ai/azure-ai-projects/azure/ai
-
https://github.com/Azure/azure-sdk-for-python/tree/main/sdk/ai/azure-ai-agents/azure/ai